TabPyによるk-meansクラスタリング
本記事では、TableauのTabPyを用いたk-meansクラスタリングを取り上げたいと思います。
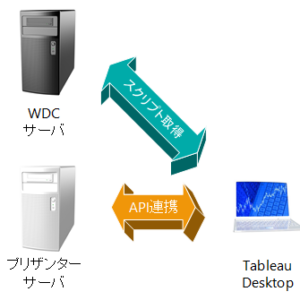
TableauとPythonの連携環境(TabPy)構築は、こちら。
データ
今回はサンプル・データとして、「Wine recognition data」を用いました。
サンプル・コード
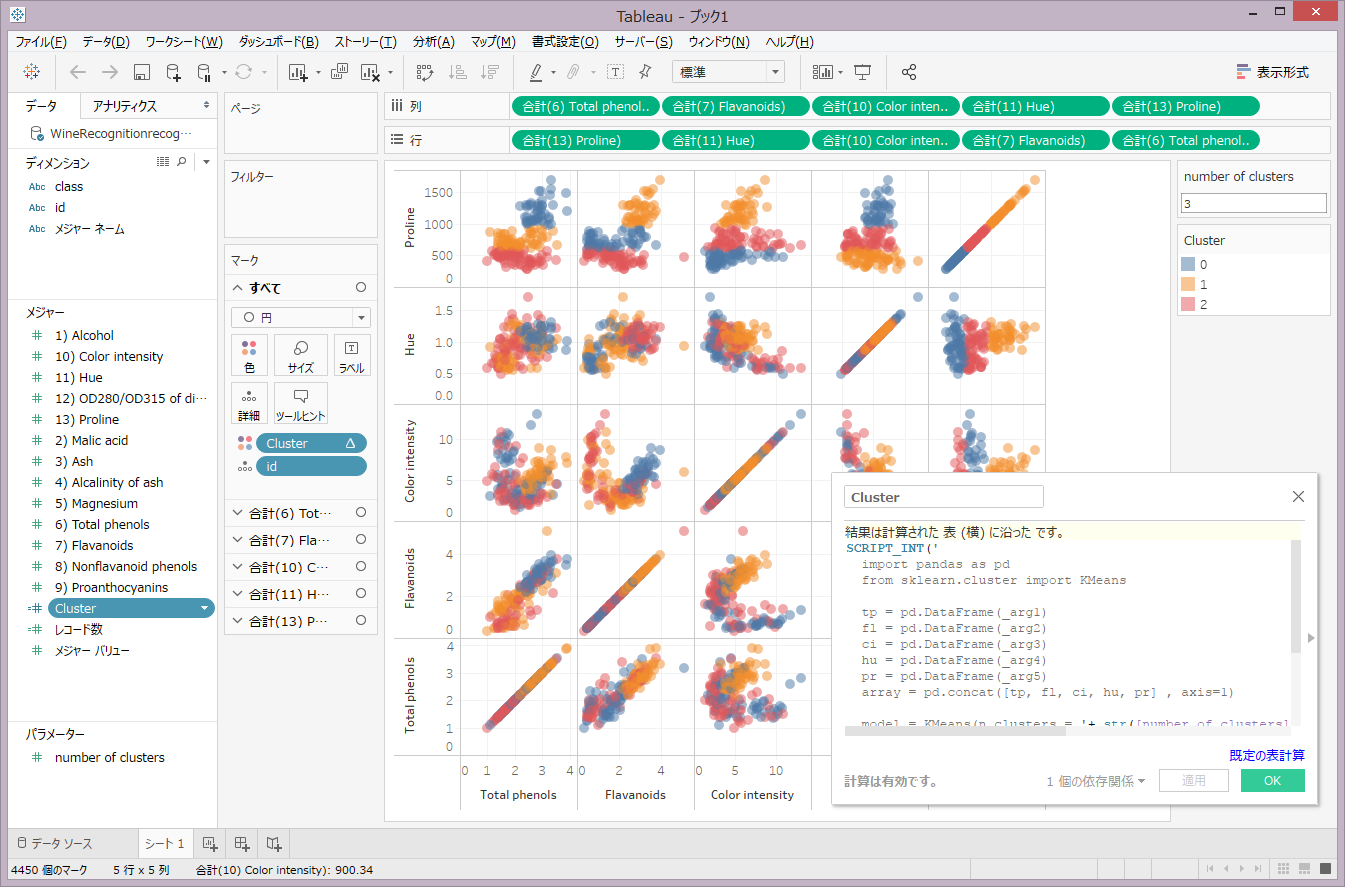
本コードでは、データセットに含まれる13個の説明変数の内、5個の説明変数(Total phenols, Flavanoids, Color intensity, Hue, Proline)を用いてクラスタリングした後、クラスタIDをTableauの計算フィールドにINT型で渡しています。
SCRIPT_INT('
import pandas as pd
from sklearn.cluster import KMeans
tp = pd.DataFrame(_arg1)
fl = pd.DataFrame(_arg2)
ci = pd.DataFrame(_arg3)
hu = pd.DataFrame(_arg4)
pr = pd.DataFrame(_arg5)
array = pd.concat([tp, fl, ci, hu, pr] , axis=1)
model = KMeans(n_clusters = '+ str([number of clusters]) +')
pred = model.fit_predict(array)
return pred.tolist()
',
SUM([6) Total phenols]), SUM([7) Flavanoids]), SUM([10) Color intensity]), SUM([11) Hue]), SUM([13) Proline])
)
図表1:スクリプトの入力例