オンプレLLMで委員意見を評価項目に結びつけるPoC:論点ラベルなし条件で試した候補生成とLLM再ランキング
生成AIやAIエージェントの活用が進む一方で、行政資料、医療・介護分野の資料、企業の内部資料など、外部AIにそのまま投入しにくい業務資料は少なくありません。本記事では、前回のオンプレLLMによる委員会資料整理PoCの追補として、委員意見を評価項目へ結びつける工程を取り上げます。論点ラベルがない資料でも、候補生成とLLM再ランキングにより、人手確認前の候補整理に使える可能性があるかを検証します。
本稿の結論:AI導入で重要なのは、全自動化ではなく確認前の候補整理
本稿の結論は、AI導入で重要なのは「最初から全自動化できるか」を問うことではなく、どの工程をAIに任せ、どこで人が確認し、どのような場合に要確認として止めるのかを設計することだ、という点です。AIエージェントの進化により、AIへ任せられる判断範囲は広がる可能性がありますが、実務では、自律度・確認点・責任分界を業務フローとして整理しておくことが重要な論点になります。
本稿で扱うPoCは、AIが最終判断者になれるかどうかを検証するものではありません。委員意見のような自由記述を、評価項目や論点に結びつける前段階として、候補生成とLLM再ランキングを組み合わせることで、人が確認すべき候補をどこまで整理できるかを確認したものです。
今後、AIエージェントが複数の判断や処理を連鎖的に実行できるようになれば、人手確認が必要な範囲はさらに小さくなる可能性があります。一方で、行政資料、医療・介護分野の資料、企業の内部資料、顧客情報を含む資料などでは、AIが出した結果をそのまま最終成果物として扱ってよいとは限りません。説明責任、確認責任、記録、例外処理を含めて、どこまでAIに任せるかを決める必要があります。
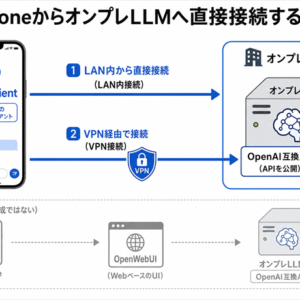
そのため、本稿では「AIで資料を完成させる」ことではなく、「人が確認する前に、候補を整理する」ことに焦点を当てます。委員意見と評価項目側の文章情報をもとに機械的に候補を生成し、LLMが候補を再ランキングし、判断が難しいものは人手確認に回す。このように工程を分けることで、外部AIに出しにくい業務資料であっても、ローカル環境やオンプレミス環境のLLMを使った現実的な導入ステップを検討できます。
今回の検証では、論点ラベルがない委員意見についても、候補生成とLLM再ランキングを組み合わせることで、人手確認前の候補整理に使える可能性があることを確認しました。一方で、これは作業時間の削減を実測したものではなく、AIだけで最終判断を確定したものでもありません。重要なのは、AIを導入するかどうかだけではなく、AIをどの工程に配置し、確認・記録・停止の仕組みをどこに設けるかを設計することです。
外部AIに出しにくい業務資料では、まず業務フローの切り分けが重要になる
生成AIを業務に使う際、最初に議論されがちなのは「どのAIを使うか」です。ChatGPT、Claude、Geminiのようなクラウド型AIを使うのか、社内環境やローカル環境で動くLLMを使うのか、RAGやAIエージェントを組み合わせるのかといった選択です。
しかし、行政資料、医療・介護分野の資料、企業の内部資料、顧客情報を含む資料などでは、AIの選定とあわせて考えるべきことがあります。それは、業務資料のどの部分をAIに扱わせ、どの範囲まで自動処理に委ね、どの場面で確認・記録・停止の仕組みを設けるのかという業務フローの切り分けです。
外部AIに出しにくい資料では、単純に「AIに要約させる」「AIに分類させる」という発想だけでは不十分です。資料の中には、AIで候補整理しやすい部分もあれば、人が確認すべき判断部分もあります。また、AIが処理できなかった場合に、結果を空欄にするのか、再実行するのか、要確認として残すのかも決めておく必要があります。
AIに任せる工程、確認・記録を残す工程、処理できなかった場合に再実行や人手確認へ戻す工程を分けておく。外部AIに出しにくい資料では、この切り分けがないままAI導入を進めると、便利さよりも確認責任や説明責任の問題が先に出やすくなります。
今回のPoCで扱った委員意見の整理も、この観点から位置づけられます。委員意見をAIに丸ごと判断させるのではなく、評価項目と結びつきそうな候補を生成し、候補順を整え、判断が難しいものは人手確認に回す。このように工程を分けることで、AIを最終判断者としてではなく、人が確認する前の整理支援として使うことができます。
そのため、本記事では、AIの性能そのものだけではなく、AIを業務フローのどこに配置するかに注目します。前回記事では、委員意見を評価指標と要確認箇所に分ける整理を扱いました。今回はその追補として、論点ラベルがない条件でも、候補生成とLLM再ランキングにより確認対象を整理できるかを見ています。
前回記事で整理したこと:委員意見を評価指標と要確認箇所に分けるPoC
前回記事では、外部AIにそのまま投入しにくい委員会資料を、オンプレミスまたはローカル環境のLLMでどこまで整理できるかを検証しました。対象としたのは、委員意見のような自由記述を、評価指標や確認すべき論点に整理する業務です。
この検証では、AIに最終判断を任せるのではなく、委員意見を評価指標に接続できるものと、人が確認すべきものに分けることを重視しました。つまり、AIで資料を完成させるのではなく、人が確認する前の整理工程を支援できるかを見ています。
委員意見を評価指標に接続できるものと、要確認として残すものに分けることで、AIに任せる工程と人が確認する工程を切り分けるPoCを行いました。重要なのは、AIで最終判断を確定することではなく、人手確認前の整理を支援することです。
前回の整理では、評価指標に結びつけられる意見だけでなく、判断が難しいものや確認を要するものも分けて扱いました。これは、実務上とても重要です。AIで処理できるものだけを見るのではなく、AIで確定しにくいものを要確認として残すことで、後続の人手確認につなげることができます。
一方で、前回の検証では、指標番号などの紐づけ情報が、委員意見と評価指標を結びつける手がかりになる場面がありました。これは実務上は有効な整理方法ですが、すべての業務資料に、最初から分かりやすい論点ラベルや整理キーが付いているとは限りません。
そこで本記事では、前回記事の追補として、論点ラベルがない条件でも、委員意見から関連しそうな評価項目の候補を生成し、LLMで再ランキングできるかを確認します。前回記事の詳細は、オンプレLLMで業務資料を整理するPoC:外部AIに出しにくい委員会資料を評価指標と要確認箇所に分けるをご参照ください。
今回確認したこと:論点ラベルがない資料でも候補を絞り込めるか
今回の追補検証で確認したのは、最初から分かりやすい論点ラベルや整理キーが付いていない資料でも、関連しそうな評価項目の候補を絞り込めるかという点です。
前回の整理では、指標番号などの紐づけ情報が、委員意見と評価指標を結びつける手がかりになる場面がありました。しかし、会議メモ、意見募集結果、ヒアリング記録、顧客対応記録などでは、文章だけが残っていることも多くあります。
実務上は、委員会議事録や会議メモの一つひとつの意見に、最初から評価指標番号や論点コードが付いているとは限りません。むしろ、後から文章を読み返し、どの論点や評価項目に関係するのかを整理し直す場面も多くあります。そのため、今回の追補検証では、あえて指標番号などの論点ラベルを使わず、本文情報だけからどこまで候補を整理できるかを確認しました。
そこで今回は、委員意見の本文と評価項目側の文章情報から、関連しそうな候補を生成しました。さらに、その候補をLLMで再ランキングし、人が確認する前に、どの評価項目から確認すべきかを整理できるかを見ています。
論点ラベルがない資料でも、本文情報から関連候補を生成し、LLMで並び替えることで、人手確認前の候補整理に使えるかを確認しました。AIで最終判断を確定するのではなく、人が確認する候補を見えやすくすることが目的です。
ここで重要なのは、AIに「正解を一つ選ばせる」ことではありません。関連しそうな評価項目を候補として並べ、人が確認しやすい状態にすることです。候補生成の段階で関連項目を拾えなかったものや、LLMの出力を解析できなかったものは、後続の人手確認や改善対象として扱います。
この考え方は、委員会資料に限らず、外部AIに出しにくい業務資料全般に応用できます。最初から論点ラベルを付けられる業務では、それを活用する方が安定しやすくなります。一方で、論点ラベルがない資料でも、候補生成、LLM再ランキング、人手確認を組み合わせることで、確認前の整理を支援できる可能性があります。
論点ラベルとは何か:AI以前に重要な入力設計
ここでいう「論点ラベル」とは、意見・発言・自由記述が、どの論点、評価項目、施策項目、業務テーマに関するものかを示す手がかりのことです。たとえば、指標番号、施策コード、議題番号、評価観点、業務分類、問い合わせ分類などが、実務上の論点ラベルにあたります。
論点ラベルが付いていると、後続の集計、突合、資料化が安定しやすくなります。委員意見と評価指標を結びつける場合でも、意見側に指標番号や施策番号が明示されていれば、機械的な整理や確認がしやすくなります。これは、AI以前の入力設計として重要なポイントです。
| 業務上の情報 | 論点ラベルの例 | 後続処理での役割 |
|---|---|---|
| 委員意見・会議意見 | 指標番号、施策項目、評価観点 | どの評価項目に関する意見かを整理する |
| 会議メモ・議事録 | 議題番号、論点番号、担当部門 | 発言や宿題事項を論点別に整理する |
| 顧客対応記録 | 問い合わせ分類、商品分類、対応ステータス | 対応状況や改善論点を分類する |
一方で、実務資料には、最初から論点ラベルが付いていないものも多くあります。自由記述の意見、メモ、ヒアリング記録、会議後の整理資料などでは、文章は残っていても、それがどの評価項目や論点に対応するのかが明示されていないことがあります。
論点ラベルがある場合は、番号や分類を手がかりに安定した整理がしやすくなります。一方で、論点ラベルがない場合は、本文情報から関連しそうな候補を生成し、人が確認する前提で候補を整理する必要があります。
今回の追補検証では、あえて指標番号などの論点ラベルを使わない条件にしました。これは、論点ラベルが整っていない資料でも、意見本文と評価項目側の文章情報をもとに、関連しそうな候補をどこまで生成できるかを確認するためです。
つまり、論点ラベルは業務整理やAI処理を安定させるための重要な入力設計です。ただし、論点ラベルがない資料でも、候補生成、LLM再ランキング、人手確認を組み合わせることで、確認前の整理を支援できる可能性があります。この点を確認するのが、今回の追補検証の目的です。
今回の検証結果:候補生成とLLM再ランキングで確認対象を絞り込める可能性
今回の追補検証では、論点ラベルを使わない条件で、委員意見を評価項目へ結びつける候補を生成し、その候補をLLMで再ランキングしました。目的は、AIだけで最終判断を確定することではなく、人が確認する前に、関連しそうな評価項目の候補をどこまで整理できるかを確認することです。
ここでいう「Top10候補」とは、1つの委員意見に対して、関連する可能性が高い評価項目を最大10件まで候補として並べたものです。今回の検証では、指標番号などの論点ラベルを使わず、意見本文と評価項目側の文章情報をもとに、関連しそうな候補を機械的に抽出しました。そのうえで、LLMにTop10候補を渡し、確認優先度が高そうな上位候補を出力させています。

左側は、委員意見の本文と評価項目側の文章情報をもとに、LLMへ投入する前段階で機械的に抽出したTop10候補です。右側は、そのTop10候補をLLMに渡し、確認優先度が高そうな上位候補を最大3件まで出力させた結果です。ここでの目的は、AIだけで最終判断を確定することではなく、人が確認すべき候補を段階的に絞り込むことです。
※ 候補生成スコアは、委員意見と評価項目候補の近さを機械的に計算した候補生成段階のスコアです。confidence は、LLMが再ランキング時に付与した信頼度ラベルであり、統計的な正解確率ではありません。
つまり、Top10候補は「AIが最終的に選んだ正解」ではありません。人が確認する前に、関連しそうな評価項目を一覧化した確認候補です。この候補の中に、前回の整理で接続済みだった評価項目、すなわち今回の検証で比較基準とした疑似正解が含まれているかを確認しました。
論点ラベルを使わない条件でも、140件中127件でTop10候補内に疑似正解を含めることができました。これは、候補生成の段階で、人が確認すべき候補を一定程度まで絞り込める可能性を示しています。
次に、候補生成で得られたTop10候補を対象に、LLMで再ランキングを行いました。LLM再ランキングの応答を解析できたものは、140件中129件、92.1%でした。一方で、request_timeoutやparse_failedなど、LLM応答や出力解析の段階で評価対象外となるケースもありました。
LLM再ランキング後の評価では、有効評価対象128件のうち96件、75.0%で疑似正解がTop1になりました。また、有効評価対象128件のうち107件、83.6%で、提示されたランキング内に疑似正解が含まれていました。
| 確認段階 | 見ていること | 結果 |
|---|---|---|
| 候補生成 | Top10候補内に疑似正解を含められたか | 127/140、90.7% |
| LLM応答解析 | LLM再ランキング結果を解析できたか | 129/140、92.1% |
| 再ランキング後のTop1一致 | 有効評価対象のうち、疑似正解がTop1になったか | 96/128、75.0% |
| 再ランキング内一致 | 有効評価対象のうち、ランキング内に疑似正解が含まれたか | 107/128、83.6% |
この結果は、AIだけで正解を確定できることを意味するものではありません。候補生成で拾えなかったもの、LLM応答がタイムアウトしたもの、出力解析に失敗したものは、人手確認候補として残す必要があります。
一方で、今回の結果は、論点ラベルがない資料であっても、候補生成とLLM再ランキングを組み合わせることで、人手確認前の候補整理に使える可能性を示しています。実務上は、AIに最終判断をすべて任せる前に、候補を絞り込み、確認・記録すべき対象を見えやすくする使い方が現実的です。
数値の見方:140件、128件、50件はそれぞれ役割が異なる
今回の検証結果を見る際に注意が必要なのは、出てくる数値の母数がすべて同じ意味ではないという点です。140件、128件、50件は、それぞれ業務フロー上の役割が異なります。
まず、140件は、前回の整理で評価項目への接続済みとして扱った委員意見です。今回の追補検証では、この140件を疑似正解付き評価対象とし、論点ラベルを使わない条件でも、本文情報からどこまで候補を生成できるかを確認しました。
次に、128件は、LLM再ランキング後の評価で有効評価対象として扱えた件数です。LLMの応答を解析できなかったケースや、評価に使えるランキング結果として扱えなかったケースは、Top1一致率やランキング内一致率を計算できません。そのため、再ランキング後の評価では、実際に評価可能だった128件を分母にしています。
140件すべてを候補生成の評価対象としましたが、LLM再ランキング後の評価では、タイムアウトや出力解析失敗などにより、Top1一致率やランキング内一致率を計算できないケースがありました。そのため、再ランキング後の一致率は、評価可能だった128件を分母にしています。
一方、50件は、前回の整理で要確認リストとして扱った委員意見です。この50件は、今回の正解率評価の対象ではありません。むしろ、実務上は人が確認すべき対象として残すべきものです。AIで無理に確定させるのではなく、確認対象として分離することに意味があります。
| 件数 | 位置づけ | 記事内での見方 |
|---|---|---|
| 140件 | 疑似正解付き評価対象 | 候補生成で、Top10候補内に比較基準となる評価項目を含められたかを見る母数 |
| 128件 | LLM再ランキング後の有効評価対象 | Top1一致率やランキング内一致率を計算する際の母数 |
| 50件 | 要確認リスト | 正解率評価対象ではなく、人手確認候補として扱う対象 |
127/140、129/140、96/128、107/128は、同じ意味の「正解率」ではありません。候補生成で拾えたか、LLM応答を解析できたか、再ランキング後に疑似正解が上位に来たかという、業務フロー上の別々の確認点を示しています。
このように母数を分けて見ることで、AI導入時にどこで失敗が起きているのか、どの工程で人手確認に戻すべきなのかを把握しやすくなります。候補生成で拾えなかったもの、LLM応答の解析に失敗したもの、要確認リストとして残したものを区別することで、AIの結果を過大評価せず、実務に組み込む際の確認ポイントを明確にできます。
したがって、今回のPoCで見るべきポイントは、単一の正解率ではありません。人が確認する前に候補をどこまで整理できたか、失敗ケースをどこで止められたか、正解率評価の対象外となる要確認リストをどう扱うかという、業務フロー全体の設計です。
失敗ケースを隠さない設計:timeout・parse_failed・Top10 missは確認・改善対象として残す
AIを実務に導入する際に重要なのは、うまく処理できたケースだけを見ることではありません。むしろ、うまく処理できなかったケースをどう記録し、どの段階で人手確認に戻すかを設計しておくことが重要です。
今回のPoCでも、すべてのケースがきれいに処理できたわけではありません。LLM応答時間の超過、出力解析の失敗、候補生成段階で疑似正解をTop10候補内に含められなかったケースが発生しました。
timeout、parse_failed、Top10 missは、AI導入を止める理由ではなく、確認・再実行・改善の対象として扱うべき確認ポイントです。重要なのは、これらを隠さず記録し、どの段階で確認や再実行に戻すかを業務フローに組み込むことです。
※ 下表は、重複のない内訳ではなく、実務上確認すべき代表的な確認ポイントを整理したものです。request_timeout と timeout以外のparse_failed は出力処理上の失敗内訳であり、Top10 miss は候補生成段階の課題を示す別軸の分類です。
| 確認ポイント | 件数 | 実務上の扱い |
|---|---|---|
| request_timeout | 8件 | LLM応答時間の超過として記録し、再実行または人手確認へ回す |
| timeout以外のparse_failed | 3件 | 出力解析に失敗したケースとして記録し、出力確認やプロンプト改善の対象にする |
| Top10 miss | 13件 | 候補生成段階で拾えなかったケースとして、人手確認または候補生成改善の対象にする |
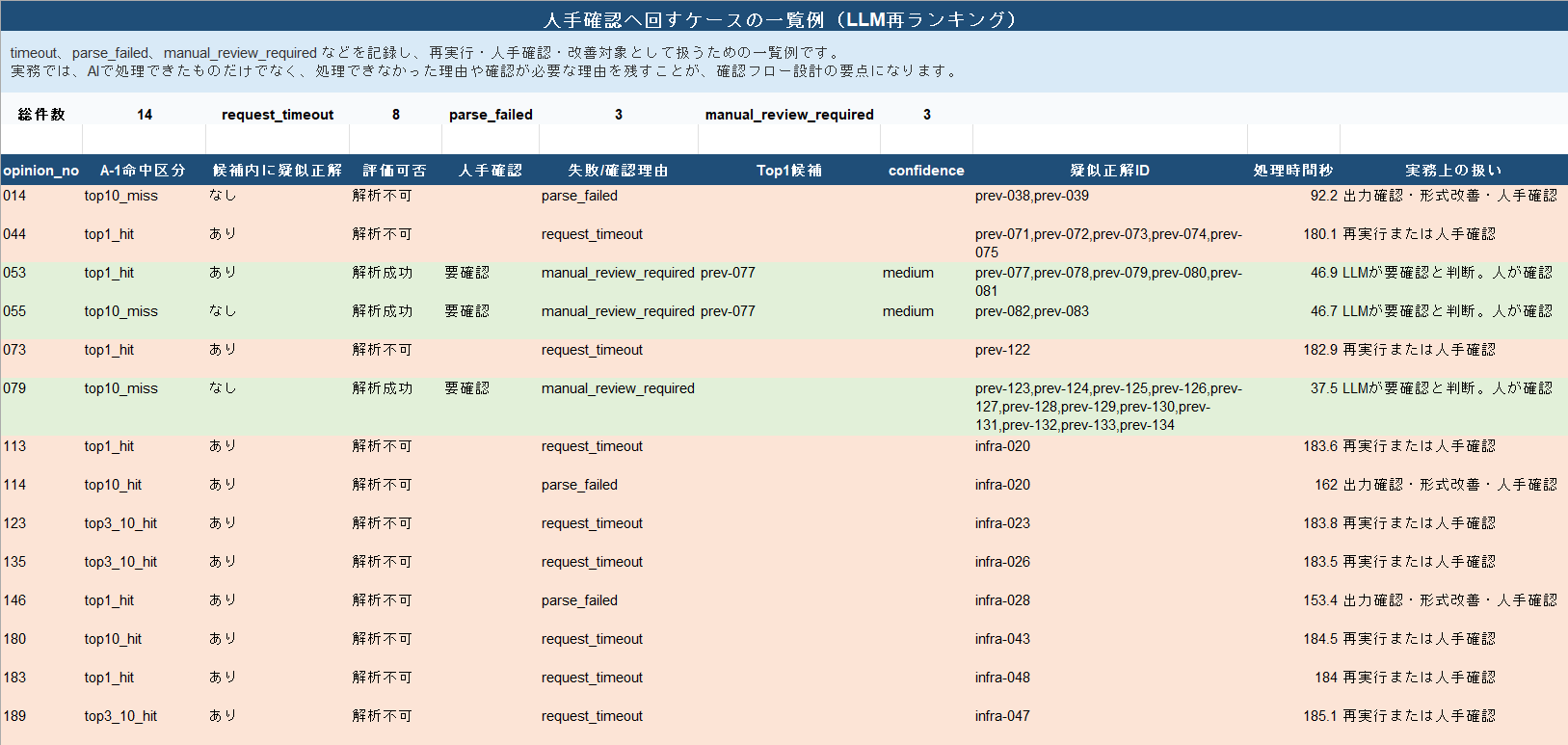
140件のうち、LLM再ランキング処理結果から人手確認ケースとして抽出した14件の一覧例です。LLM再ランキングでは、timeout、parse_failed、manual_review_required など、人手確認や再実行が必要になるケースも発生します。実務では、AIで処理できなかった理由や確認が必要な理由を記録し、再実行、人手確認、改善の対象として扱うことが重要になります。
request_timeoutは、LLMからの応答が所定時間内に返らなかったケースです。これは、AIの判断内容が誤っていたというより、処理時間や実行環境に起因する処理上の問題です。実務では、こうしたケースを失敗として隠すのではなく、再実行対象または人手確認対象として記録しておく必要があります。
parse_failedは、LLMの出力を期待した形式で解析できなかったケースです。生成AIは、指示した形式から外れた回答を返すことがあります。そのため、実務で使う場合には、出力形式のチェック、解析失敗時の記録、再実行や人手確認への分岐をあらかじめ設計しておく必要があります。
Top10 missは、候補生成の段階で、比較基準とした評価項目がTop10候補内に入らなかったケースです。この場合、後段のLLM再ランキングでは、候補に含まれていないものを選ぶことはできません。つまり、再ランキングの問題というより、候補生成段階での拾い上げの問題として扱う必要があります。
このように失敗ケースを分けて扱うことで、AIの結果を過信せず、実務上の確認ポイントを明確にできます。AIに任せられる範囲が広がったとしても、説明責任や確認責任が伴う業務では、うまく処理できなかったケースを人手確認へ戻す設計が重要になります。
今回のPoCで重要なのは、AIがすべてを正しく処理したことではありません。処理できたもの、処理できなかったもの、候補生成で拾えなかったものを分けて記録し、人が確認すべき対象を明確にできることです。この設計があることで、外部AIに出しにくい業務資料でも、AI支援を現実的に業務フローへ組み込む余地が生まれます。
実務上の示唆:AI導入時に設計すべき3つの分担
今回のPoCから得られる実務上の示唆は、単に「LLMで分類できるかどうか」ではありません。むしろ重要なのは、AI導入時に、業務をどのような工程に分け、どこまでをAIに任せ、どの場面で確認・記録・停止の仕組みを設けるかをあらかじめ整理することです。
特に、外部AIに出しにくい業務資料を扱う場合、便利なAIサービスをそのまま使うかどうかだけで判断するのは十分ではありません。入力設計、AIによる候補整理、確認・記録・判断の仕組みという3つの分担を明確にすることで、ローカル環境やオンプレミス環境のLLMを現実的に活用しやすくなります。
入力設計:後から整理しやすい形で情報を集める
第一に重要なのは、AIに処理させる前の入力設計です。前回の整理では、指標番号のような紐づけ情報が、委員意見と評価指標を結びつける手がかりになっていました。一般の業務でいえば、論点番号、議題番号、施策項目、評価観点、業務テーマ、分類コードなどが、後続処理のための論点ラベルにあたります。これらは、集計・突合・資料化の場面では、実務上の整理キーとして機能します。
一方で、今回の追補検証では、このような論点ラベルを使わず、意見本文から関連しそうな評価項目の候補を生成し、LLMで再ランキングしました。この違いを分けて考えることが重要です。論点ラベルを付与できる業務では、最初から付与しておく方が安定しやすくなりますが、ラベルがない資料でも、候補生成と人手確認を組み合わせることで整理支援できる可能性があります。
AI導入の前に、意見・発言・自由記述をどの論点や評価項目に結びつけたいのかを整理する。論点ラベルを付けられる業務では、最初から付けておく方が安定しやすい。一方で、論点ラベルがない資料では、候補生成と人手確認を前提にした整理フローを設計する。
AI支援:論点ラベルがない資料では、候補を整理する
第二に、論点ラベルがない資料では、AIを「最終判断者」ではなく「候補整理の支援役」として使うことが現実的です。通常の自由記述、会議メモ、委員意見、顧客対応記録などでは、最初から論点ラベルが付いていないことも少なくありません。その場合、本文情報から関連しそうな評価項目や論点を候補として生成し、LLMで再ランキングする方法が考えられます。
今回の検証では、論点ラベルを使わない条件でも、140件中127件でTop10候補内に疑似正解を含めることができました。また、LLM再ランキング後、有効評価対象128件中96件で疑似正解がTop1になりました。これは、AIだけで最終確定できることを意味するものではありませんが、人手確認前の候補整理に使える可能性を示しています。
論点ラベルがない資料では、AIに最終判断を任せるのではなく、候補生成とLLM再ランキングにより、人が確認する前の候補を整理する。
確認・記録・停止:失敗ケースや判断が難しいものを残す
第三に、確認・記録・停止の設計が必要です。AIを実務に使う場合、うまく処理できたものだけを見るのではなく、うまく処理できなかったものをどう扱うかが重要になります。今回のPoCでも、timeout、parse_failed、Top10 missといったケースが発生しました。
こうしたケースを無理に自動処理で確定させるのではなく、確認・再実行・改善の対象として残すことが重要です。AIが処理できなかったものや判断が難しいものを隠さず、記録し、確認対象として分離することで、実務上の安全性と説明可能性を高めることができます。
timeout、parse_failed、候補生成で拾えなかったもの、判断が難しいものは、無理にAIで確定せず、確認・再実行・改善の対象として分離する。
この3つの分担を整理すると、AI導入の論点は「AIを使うか、使わないか」だけではなくなります。どの情報を、どの工程で、どの環境のAIに扱わせるのか。どこまでを候補整理として扱い、どの場面で確認・記録・判断に戻すのか。その設計こそが、外部AIに出しにくい業務資料を扱う際の重要な検討事項になります。
AIエージェントの性能が向上すれば、AIに任せられる範囲は広がる可能性があります。それでも、説明責任や確認責任が伴う業務では、入力設計、AI支援、確認・記録・停止の役割分担を明確にすることが、現実的な導入ステップになります。
今後の改善余地:精度向上より先に、確認フローを設計する
今回のPoCには、当然ながら改善余地があります。候補生成の方法を改善する、LLMへの指示を調整する、再ランキングの出力形式を安定させる、timeoutを減らす、といった技術的な改善は考えられます。
ただし、実務導入を考える場合、最初に見るべきなのは単純な精度向上だけではありません。むしろ重要なのは、AIがうまく処理できたもの、処理できなかったもの、人が確認すべきものを、業務フロー上でどう分けるかです。
精度を上げることだけを目的にするのではなく、候補生成、LLM再ランキング、出力解析、人手確認、再実行、要確認リスト化という流れを業務フローとして設計することが重要です。
たとえば、Top10 missが発生したケースは、候補生成段階で関連候補を拾えていない可能性があります。この場合は、候補生成に使う文章情報を増やす、評価項目側の説明文を整える、検索条件や類似度計算の方法を見直すといった改善が考えられます。
request_timeoutが発生したケースは、LLMの判断内容そのものよりも、処理時間や実行環境の問題として扱う必要があります。実務では、timeoutしたものをそのまま消すのではなく、再実行対象として記録する、再実行しても処理できない場合は人手確認へ回す、といった分岐をあらかじめ決めておく必要があります。
parse_failedが発生したケースは、LLMの出力形式を安定させる設計が必要です。たとえば、出力フォーマットを固定する、解析できなかった出力をログとして残す、再実行用のプロンプトを分ける、解析失敗時には人手確認用レポートに回すといった対応が考えられます。
| 改善対象 | 主な課題 | 改善の方向性 |
|---|---|---|
| 候補生成 | 関連候補をTop10内に拾えないケースがある | 本文情報、評価項目側の説明、検索条件、類似度計算を見直す |
| LLM再ランキング | 応答時間の超過や判断のばらつきが起こり得る | 再実行ルール、候補数、プロンプト、実行環境を調整する |
| 出力解析 | LLM出力を期待した形式で解析できない場合がある | 出力形式を固定し、解析失敗時のログ化と人手確認への分岐を設ける |
| 確認・記録 | どこを確認・記録すべきかが見えにくい | 確認用レポート、要確認フラグ、候補一覧、判断理由欄を用意する |
特に実務上は、人手確認や記録に使うレポート設計が重要になります。AIが出した候補、LLM再ランキングの順位、要確認フラグ、処理できなかった理由や確認が必要な理由、確認者が判断を書く欄をまとめておけば、AIの結果をそのまま信じるのではなく、人が確認しやすい形で活用できます。
この意味で、AI導入の改善は「精度を上げる」ことだけではありません。精度を上げる取り組みと並行して、失敗した場合に止める仕組み、確認対象を残す仕組み、確認結果を記録する仕組みを整える必要があります。
今回のPoCは、完成した業務システムではありません。むしろ、外部AIに出しにくい資料を扱う際に、どの工程をAIに任せ、どこで人が確認し、どのようなケースを要確認として残すべきかを考えるための検証です。今後の改善でも、単純な正解率だけではなく、確認フロー全体の設計を重視する必要があります。
まとめ:業務設計とAI支援を組み合わせることが、現実的な導入ステップ
今回の追補検証では、論点ラベルがない委員意見についても、候補生成とLLM再ランキングを組み合わせることで、人手確認前の候補整理に使える可能性があることを確認しました。
一方で、これはAIだけで最終判断を確定できることを意味するものではありません。候補生成で拾えなかったもの、LLM応答がタイムアウトしたもの、出力解析に失敗したものは、人が確認すべき対象として残す必要があります。また、今回の検証は作業時間の削減を実測したものでもありません。
重要なのは、AIを導入するかどうかだけではなく、どの業務工程にAIを配置するかです。入力資料をどう整えるか、AIにどこまで候補整理を任せるか、どの段階で人が確認するか、処理できなかったものをどう記録するか。こうした業務設計とAI支援を組み合わせることが、外部AIに出しにくい資料を扱う際の現実的な導入ステップになります。
AIに最終判断を任せるのではなく、人が確認する前の候補整理に使う。論点ラベルがある場合は入力設計として活用し、論点ラベルがない場合は候補生成、LLM再ランキング、確認・記録・停止の仕組みを組み合わせる。処理できなかったものは隠さず、確認・再実行・改善の対象として業務フローに戻す。
生成AIやAIエージェントの性能が向上すれば、AIに任せられる範囲は今後さらに広がる可能性があります。しかし、行政資料、医療・介護分野の資料、企業の内部資料、顧客情報を含む資料などでは、便利なAIをそのまま使えばよいとは限りません。説明責任、確認責任、記録、例外処理を含めて、業務フロー全体を設計する必要があります。
今回のPoCは、完成した業務システムではなく、外部AIに出しにくい業務資料をどのようにAI支援の対象にできるかを検討するための実務検証です。AIで何を自動化するかだけでなく、どこで人が確認し、どの情報をどの環境で扱うかを設計することが、これからのAI導入では重要な論点になります。
前回記事では、委員意見を評価指標と要確認箇所に分けるPoCを整理しました。本記事では、その追補として、論点ラベルがない条件でも候補生成とLLM再ランキングにより確認対象を整理できるかを確認しました。前回記事の詳細は、オンプレLLMで業務資料を整理するPoC:外部AIに出しにくい委員会資料を評価指標と要確認箇所に分けるをご参照ください。
※ 本記事は、公開資料をもとにしたPoCの整理であり、特定の会議資料や行政判断を評価・予測するものではありません。また、記事中の数値は検証条件下での結果であり、実際の業務環境で同じ結果を保証するものではありません。
関連記事