源内OSS公開を機に考えるオンプレRAG:外部AIアプリAPIの考え方をFastAPI+FAISS+NVIDIA Blackwell (GB10) 想定で最小実装する
【導入】源内OSS公開を機に、オンプレRAGを考える
デジタル庁のガバメントAI「源内」のOSS公開は、生成AIを単なるチャットツールとしてではなく、業務アプリケーション基盤としてどう設計するかを考えるきっかけになります。
一方で、源内のような生成AI活用基盤を参考にしながら、まずは小さくRAGや業務AIアプリを試そうとすると、クラウドLLM APIの課金感、データ送信範囲、閉域性、GPU資源、運用体制といった論点を早い段階で整理しておく必要があります。
そこで本記事では、「源内をオンプレミスで再現する」ことではなく、源内OSSで示されている外部AIアプリAPIという境界に注目します。Web UI、RAG検索、LLM推論環境を分けて考えることで、ローカル環境でも検討しやすい最小構成を整理します。
この記事で作るもの、作らないもの
- 作るもの:
/api/invokeを中心にしたローカルRAG APIデモ - 作らないもの:源内Webの再現、OpenWebUIの代替、本番基盤
本記事の実装は、デジタル庁が公開した源内Webそのもの、または公式
genai-web 互換UIを再現するものではありません。また、源内オンプレ版やOpenWebUIの代替を目的とするものでもありません。
源内OSS公開をきっかけに、共通Webインターフェースから外部AIアプリAPIを呼び出すという境界に着目し、RAGを行う最小API構成をローカル環境で検証するものです。
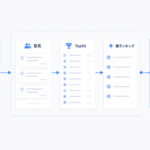
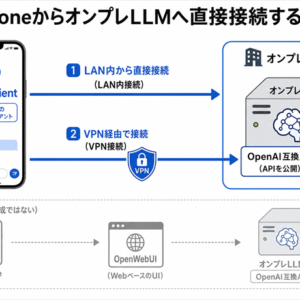
全体像:Web UI、API、RAG、LLM推論を分離する
今回の構成では、Browser から Vite + React Web UI を通じて FastAPI の /api/invoke に inputs を送ります。
RAGモードでは、FastAPI側でFAISS検索を行い、取得したローカル文書チャンクをOpenAI互換LLM APIへ渡して、回答を outputs として返します。
/api/invokeを呼び出し、inputsを送りoutputsを受け取る流れを確認できます。画像をクリックすると拡大表示できます。
過去のAWS EC2 + Ollama + OpenWebUI RAG検証で見えた課題
以前、AWS EC2上にOllamaとOpenWebUIを組み合わせ、プライベートLLMとRAGを検証しました。OpenWebUIのような完成度の高いUIを使うと、ローカルLLMやRAGを短時間で試せる一方で、業務AIアプリとして見た場合には、UI、RAG処理、LLM推論、運用環境の境界をどこで分けるかが課題になります。
特に、組織内の業務データや文書を扱う場合、チャットUIを導入するだけではなく、どのAPIが入力を受け、どこで検索し、どこでLLMを呼び、どのように参照情報を返すのかを整理する必要があります。本記事では、その課題意識を引き継ぎ、より小さなAPI境界として /api/invoke を実装しています。
源内OSSの全体像と、本記事が注目する範囲
源内OSSで注目したいのは、単にWeb UIの見た目ではなく、利用者が触るWebインターフェースと、実際に生成AI処理を行う外部AIアプリAPIを分けて考える構造です。
公開されている源内Webの説明では、源内Webは「AIインターフェース」として機能し、別リポジトリで管理されるAIアプリと連携する構成が示されています。また、源内Web側にはチーム管理機能、AIアプリ管理機能、外部マイクロサービスとして構築した生成AIアプリの追加・実行機能などが含まれています。
本記事では、この源内Web全体を再現するのではなく、その中でも特に「共通Webインターフェースから外部AIアプリAPIを呼び出す」という境界に注目します。Web UI、AIアプリAPI、RAG検索、LLM推論環境を分けて考えることで、オンプレミス環境やLAN内検証でも理解しやすい最小構成として整理します。
この考え方は、古典的なWebアプリケーション設計でいうMVCをそのまま当てはめるものではありません。ただし、画面、入力を受けるAPI、業務処理、データや検索処理を分けて考えるという意味では、従来の責務分離の発想と地続きです。生成AIアプリでも、UIとLLM呼び出しを一体化させすぎず、どこで入力を受け、どこで検索し、どこで推論するのかを分けておくことが重要になります。
源内OSSの全体像を理解するうえでは、源内Web、外部AIアプリAPI、クラウド基盤、認証・管理機能などをまとめて見る必要があります。ただし、本記事ではそれらを網羅的に解説するのではなく、オンプレミスRAGの検討に直接関係する「Web UIとAIアプリAPIの分離」に絞って扱います。
源内OSSの概略イメージ
利用者
↓
源内 Web(AIインターフェース)
├─ チーム管理・AIアプリ管理
├─ 外部AIアプリの追加・実行
└─ AIアプリ連携
↓
源内AIアプリ
└─ 生成AI処理・RAG・外部サービス連携など※公式リポジトリ・公開資料の説明をもとに、本記事用に概略化した図です。実際の源内Webの全モジュール、AIアプリ実装、クラウド構成を網羅したものではありません。
本記事の軽量実装イメージ
Browser
↓
Vite + React Web UI
↓
FastAPI /api/invoke
├─ mock mode
├─ LLM proxy mode
└─ FAISS RAG mode
├─ HashingVectorizer + FAISS
├─ local documents
├─ RAG context validation
└─ OpenAI-Compatible LLM API
↓
{ "outputs": "..." }本記事では、源内Web全体ではなく、inputs を受け取り outputs を返す外部AIアプリAPIの境界を、FastAPI + FAISS + OpenAI互換LLM APIで最小実装します。
| 項目 | 源内OSSの全体像 | 今回の軽量実装 |
|---|---|---|
| 主眼 | 生成AI活用基盤全体 | 外部AIアプリAPI境界の最小検証 |
| UI | 源内 Web(AIインターフェース) | Vite + React の検証用Web UI |
| API境界 | Web UIから外部AIアプリを呼び出す構成 | /api/invoke で inputs を受け取り outputs を返す構成 |
| AIアプリ | 外部マイクロサービスとして追加・実行される生成AIアプリ | mock / LLM proxy / FAISS RAG の3モード |
| RAG検索 | 用途に応じたAIアプリ側の実装領域 | HashingVectorizer + FAISS による軽量ローカル文書検索 |
| LLM推論環境 | クラウド基盤や外部AI環境を含む全体設計 | NVIDIA Blackwell (GB10) 搭載機などのOpenAI互換LLM APIを外部推論サーバーとして呼び出す想定 |
| 扱わないもの | チーム管理、認証、監視、運用、本番基盤などを含む広い構成 | 認証、DB、Nginx、本番デプロイ、公式UI互換、源内Web再現は扱わない |
| 目的 | 組織的な生成AI活用基盤 | 源内OSSの考え方を参考に、オンプレRAGの構成要素を小さく理解する |
この比較から分かるように、本記事の実装は源内Webの置き換えではありません。共通Webインターフェースと外部AIアプリAPIを分ける考え方だけを取り出し、RAGを行う最小APIとしてローカル環境で検証するものです。
今回の最小構成:FastAPI + FAISS + NVIDIA Blackwell (GB10)
今回の構成では、FastAPIをAIアプリAPIの入口とし、FAISSでローカル文書を検索し、OpenAI互換LLM APIへ問い合わせる形にしました。LLM推論環境そのものはこのリポジトリには含めず、NVIDIA Blackwell (GB10) 搭載機上のOpenAI互換APIなど、LAN内の推論サーバーを呼び出す想定です。
RAGの検索部分は、HashingVectorizer + FAISS の軽量構成にしています。これは本格的な意味検索の品質を狙うものではなく、外部AIアプリAPIとRAG処理をどのように分離できるかを確認するための最小構成です。
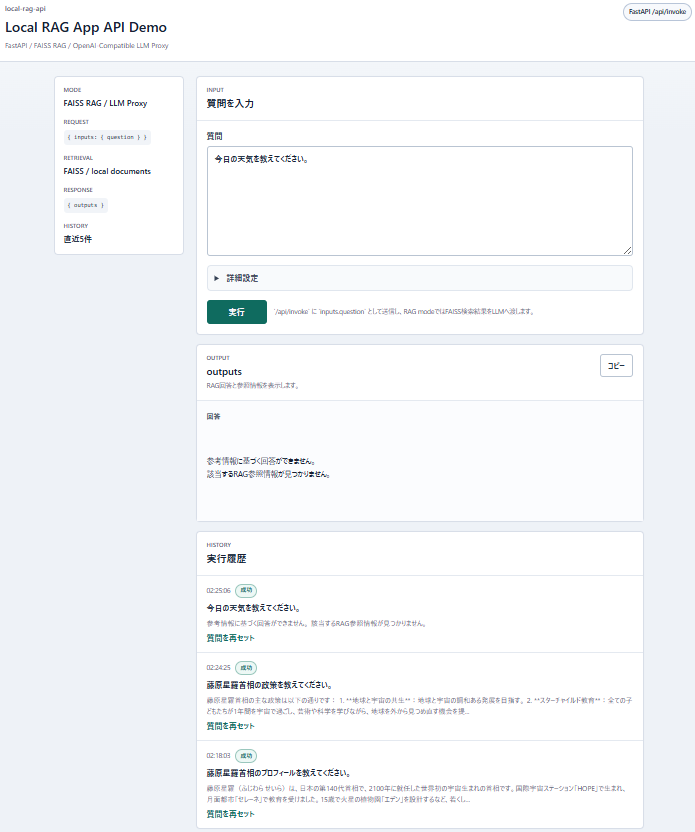
/api/invoke:inputs -> outputs の最小API
今回のAPIは、リクエストで inputs を受け取り、レスポンスで outputs を返す最小形にしています。
{
"inputs": {
"question": "藤原星羅首相のプロフィールを教えてください。"
}
}{
"outputs": "回答本文...\n\n参照:\n- fujiwara_seira.txt#0"
}RAGの参照情報は、現時点では outputs 文字列の末尾に「参照:」セクションとして付けています。より構造化したAPIにする場合は、将来的に sources フィールドとして分ける設計も考えられます。
mock / LLM proxy / FAISS RAG の3モード
今回の実装では、いきなりRAGだけを作るのではなく、段階的に確認できるようにしています。
- mock mode:LLMやRAGに依存せず、
/api/invokeの疎通とAPI外形を確認するモード - LLM proxy mode:入力された質問をOpenAI互換LLM APIへ転送し、回答を
outputsとして返すモード - FAISS RAG mode:FAISSでローカル文書を検索し、取得チャンクをプロンプトに含めてLLMへ渡すモード
FAISS RAGの処理フロー
RAGモードでは、まず inputs.question を取り出し、FAISSでローカル文書チャンクを検索します。検索結果のうち、一定スコア以上の候補を残し、質問との簡易的な重なりを確認したうえで、RAGプロンプトを組み立てます。
有効なRAG文脈がある場合だけOpenAI互換LLM APIを呼び出し、回答本文の末尾に参照情報を付けて outputs として返します。
Web UIで確認する:回答と参照情報の分離表示
以下の動作確認では、RAG検証用の架空データ「藤原星羅」を使います。実在する人物・組織・政策・将来予測とは関係ありません。
第1弾のAWS EC2 + Ollama + OpenWebUI RAG検証記事と比較しやすいように、今回も同じ架空データをRAG用参照データとして使っています。
RAG用参照データ(フィクション)を表示する
※以下のデータはRAG検証用のフィクションであり、実在する人物、組織、政策、企業、製品、事例とは一切関係ありません。
日本の第140代首相である藤原星羅(ふじわら せいら)は、2100年に就任した世界初の宇宙生まれの首相です。
彼女は国際宇宙ステーション「HOPE」での誕生後、月面都市「セレーネ」で教育を受け、15歳で火星の植物園「エデン」を設計するなど、早くから才能を発揮しました。
地球と宇宙の共生を政策の中心に掲げる彼女は、「スターチャイルド教育」を推進。
全ての子どもたちが1年間を宇宙で過ごし、芸術や科学を学びながら、母なる地球を外から見つめ直す機会を創出しています。
量子テレポーテーション技術を活用した「どこでもドア交通網」により、東京-月間15分、火星まで1時間という「宇宙通勤時代」を実現。
さらに、AI制御の重力調整により、宇宙空間でも地球と同じように暮らせる「スペースライフ」を標準化しました。
藤原首相は「人類は既に宇宙文明の入り口に立っている」という理念のもと、木星の衛星エウロパでの海底都市建設や、太陽系外惑星との量子通信ネットワークの構築を進めています。
また、地球の環境再生技術を応用した「テラフォーミング」プロジェクトでは、火星に青い空と海をもたらすことを目指しています。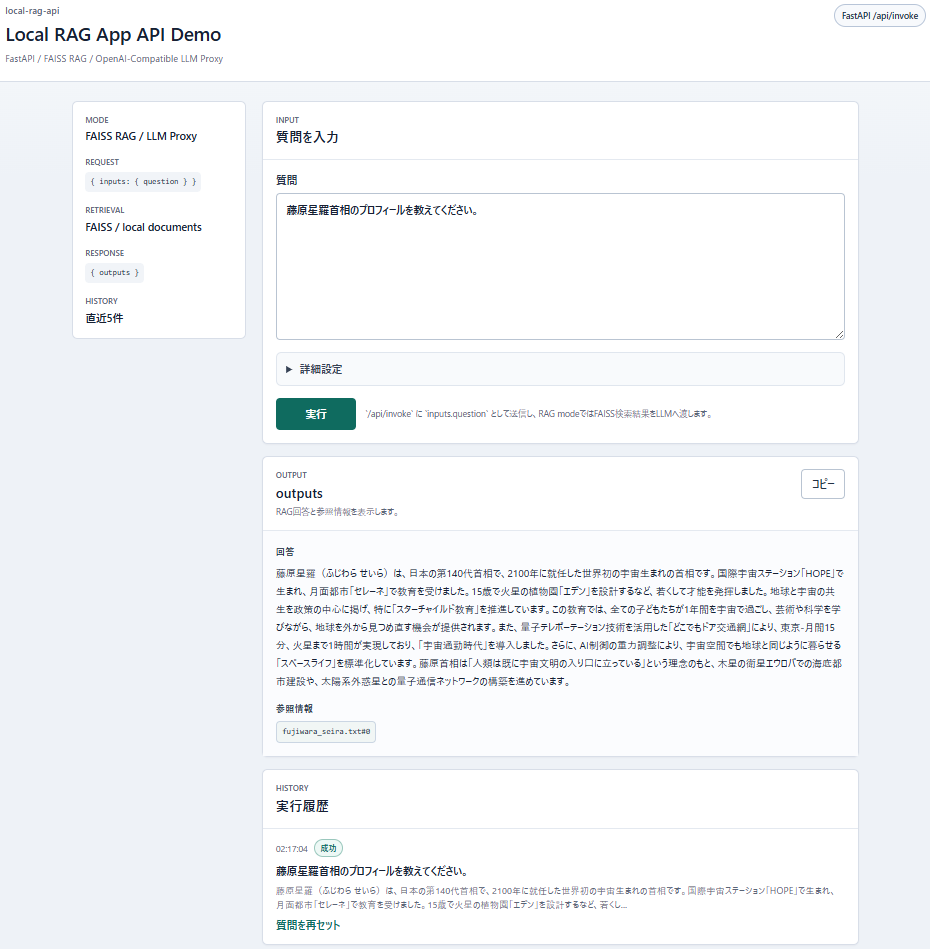
画像をクリックすると拡大表示できます。
プロフィール質問だけでなく、政策に関する質問でも、取得したローカル文書チャンクに基づく回答と参照情報を確認できます。
RAG対象外質問ではLLMを呼ばない
軽量な HashingVectorizer + FAISS 構成では、RAG対象外の質問でも何らかの検索候補が返る場合があります。しかし、検索候補があることと、回答根拠として採用してよいことは別です。
今回の実装では、LLMを呼び出す前に、検索スコアに加えて、質問と候補チャンクの簡易的な文字 n-gram 重なりを確認します。有効なRAG文脈がないと判断した場合は、LLMを呼ばず、固定メッセージを返します。
たとえば「今日の天気を教えてください。」のように、ローカル文書と関係しない質問では、次の固定メッセージを返します。
参考情報に基づく回答ができません。
該当するRAG参照情報が見つかりません。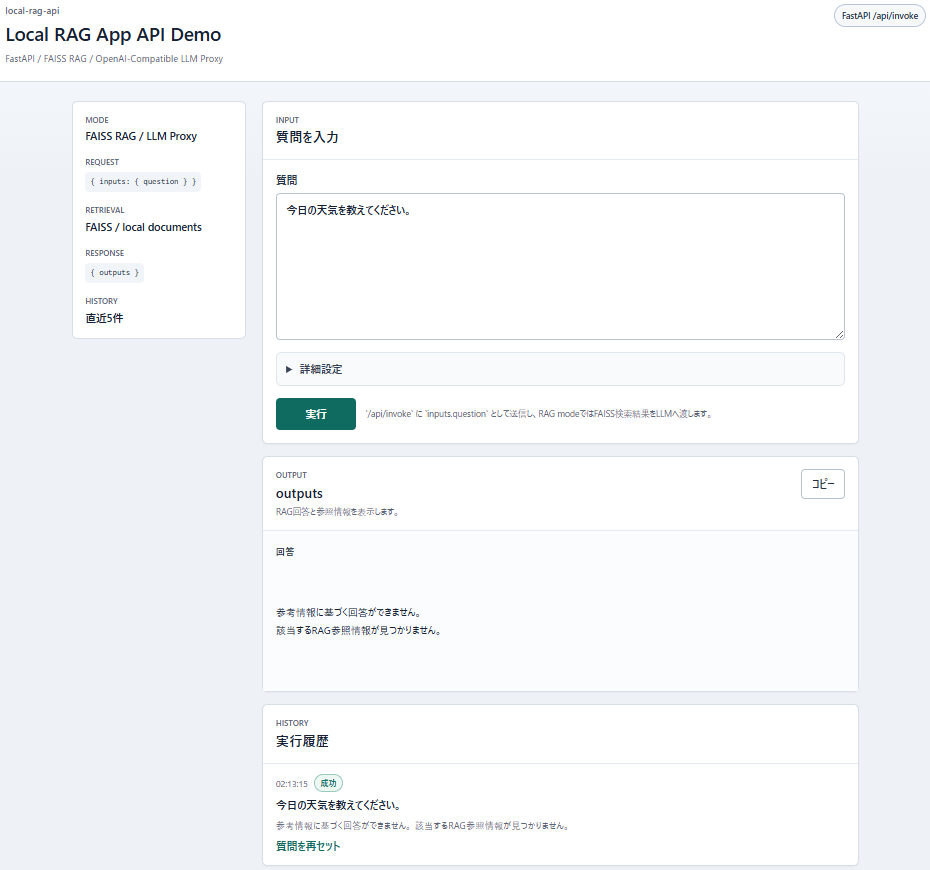
画像をクリックすると拡大表示できます。
OpenWebUIの代替ではなく、業務AIアプリ基盤の分解記事
OpenWebUIは、ローカルLLMやRAGを素早く試すうえで非常に便利な完成品UIです。一方で、本記事の目的はOpenWebUIを置き換えることではありません。
今回重視したのは、Web UI、AIアプリAPI、RAG検索、LLM推論環境を分けて考えることです。源内OSSで示されている外部AIアプリAPIの考え方を参考にしながら、業務AIアプリ基盤の構成要素を小さく分解して確認することを目的にしています。
今回あえて実装しなかったこと
sources 別フィールド化は今回は見送る
RAG APIとしては、参照情報を outputs とは別の sources フィールドとして返す設計も考えられます。ただし今回は、外部AIアプリAPIの最小形を確認することを優先し、outputs 文字列内の「参照:」セクションとして扱いました。
認証、DB、本番デプロイは扱わない
本記事の目的は、本番向けの生成AI業務基盤を完成させることではありません。認証、権限管理、DB、Nginx、本番デプロイなどは、今回のローカル検証スコープから外しています。
今後の検討余地
- RAG参照情報を
sourcesフィールドとして構造化する - BM25 + FAISS など、キーワード検索とベクトル検索を組み合わせる
- 複数文書を扱えるようにする
- 参照チャンク本文をWeb UI上で展開表示する
【結び】小さく分解することで、業務AIアプリ基盤を理解する
源内OSSの公開は、生成AIを「チャット画面」ではなく、業務アプリケーション基盤として捉え直すきっかけになります。
本記事では、その全体を再現するのではなく、外部AIアプリAPIという境界に絞り、Web UI、RAG検索、LLM推論を分離した最小構成として検証しました。まずは構成要素を小さく分解して理解することが、ローカル環境でRAGや業務AIアプリを検討するうえでの現実的な第一歩になると考えています。
関連記事