【初心者向け】AWS EC2×Docker×Ollama×Open WebUIでプライベートLLM環境を構築!
〜RAG対応スマートAIアシスタントの作り方〜
本記事では、プライベートなLLM環境をAWS EC2上に構築する方法について、初心者の方にも分かりやすく解説していきます。
見出し
はじめに
プライベートLLM環境の特徴
- 長所:
- データプライバシーの確保:社内文書や個人情報を外部サービス不要で扱えます
- 環境のカスタマイズ性:独自のニーズに合わせた環境構築が可能です
- 課題:
- インフラ運用コスト:サーバー費用やリソース管理の手間が必要です
- 処理能力の制約:商用APIと比べて処理速度や性能が限定的な場合があります
- 継続的な保守:モデルやシステムの更新を自身で管理する必要があります
本環境の特徴
- AWS EC2とDockerを活用した実行環境
- OllamaとOpen WebUIの組み合わせで使いやすいインターフェース
- RAG(検索拡張生成)機能による独自データ活用
対象読者
- AWSとDockerの基礎知識をお持ちの方
- プライバシーを重視したAI環境に興味のある方
システム構成と準備
システム構成の全体像
クラウド上のサーバーにプライベートLLM環境を構築し、1つの仮想環境(Dockerコンテナ)内でOllama(オープンソースのLLMサーバー)とOpen WebUI(使いやすいWebインターフェース)を稼働させる構成となっています。
図表1:プライベートLLM環境のシステム構成概要
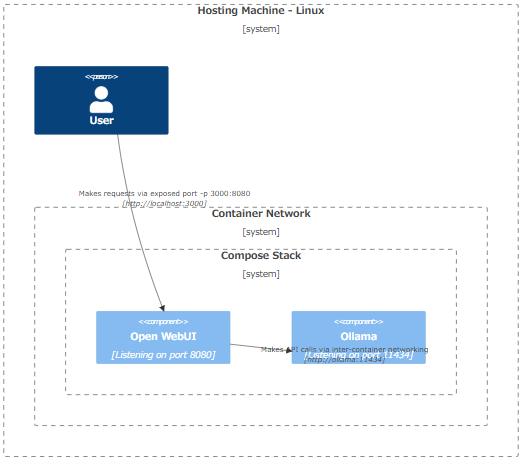
出所:「Ollama and Open WebUI in Compose Stack (Linux)」(Open WebUI)
必要なコンポーネントと要件
本環境を構築するために必要な主要コンポーネントと要件は以下の通りです:
- ハードウェア要件:
- CPU: 8コア以上推奨
- RAM: 16GB以上推奨
- ストレージ: SSDストレージ推奨(100GB以上が望ましい、モデルのサイズによる)
- GPU: NVIDIA GPU(推奨、CPUでも実行可能)
- ソフトウェア要件:
- AWSアカウントとアクセス権限
- Ubuntu Server 24.04 LTS(本記事での実際の構築環境)
- ネットワーク要件:
- 安定したインターネット接続
- 固定IPアドレスまたはElastic IP(AWS専用の固定IPサービス)
- 適切に設定されたセキュリティグループ
これらは安定性とパフォーマンスを確保するための推奨値です。実際の要件は、使用するLLMモデルのサイズと想定負荷により変動します。
AWS EC2インスタンスのセットアップと初期設定
AWS EC2(Amazon Elastic Compute Cloud)は、クラウド上で仮想サーバーを提供するサービスです。この仮想サーバーのことを「インスタンス」と呼び、必要な性能やリソースに応じて様々なタイプから選択できます。
インスタンスの作成
- インスタンスタイプの選択
- g5g.2xlargeを選択(8 vCPU, 16 GiB RAM, NVIDIA T4 GPU搭載)
- AWS Gravitonプロセッサ(ARM系CPU)採用により、コスト効率の良い運用が可能
- GPU対応インスタンスにより、LLMの推論性能を効率的に活用可能
- AMI(Amazon Machine Image)の選択
- 「Ubuntu Server 24.04 LTS (HVM), SSD Volume Type」のARM64版を選択
- ARM64アーキテクチャに最適化された OS イメージを使用
- 長期サポート版(LTS)により、運用の安定性を確保
- ストレージ設定
- ルートボリューム:100GB(gp3)を推奨
- LLMモデルやRAG用データの保存に十分な容量を確保
- ネットワーク設定
- 新規VPCを作成し、パブリックサブネットに配置
- Elastic IPを割り当てて固定IPアドレスを確保
セキュリティ設定
- セキュリティグループの作成
- SSH(TCP 22)ポートは管理者IPアドレスからのアクセスのみに制限
- Open WebUI用のポート(TCP 7860)に対して適切なアクセス制御を設定
- その他の不要なポートは原則として閉じておく
- 定期的なセキュリティグループルールの見直しと更新を推奨
SSH接続
- SSH鍵を使用した安全な接続方法を確認
Dockerによる環境構築
Dockerのインストールと初期設定
# システムの更新
sudo apt update && sudo apt upgrade -y
# 必要なパッケージのインストール
sudo apt install -y ca-certificates curl gnupg
# Dockerの公式GPGキーを追加
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Dockerリポジトリの設定
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# Dockerパッケージのインストール
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# ユーザーをdockerグループに追加
sudo usermod -aG docker $USER
newgrp docker
NVIDIAドライバーとNVIDIA Container Toolkitのインストール
# NVIDIAドライバーのインストール
sudo apt install -y nvidia-driver-535 nvidia-utils-535
# NVIDIA Container Toolkitのリポジトリ設定
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# NVIDIA Container Toolkitのインストールと設定
sudo apt update && sudo apt install -y nvidia-container-toolkit
# Docker再起動でGPUサポートを有効化
sudo systemctl restart docker
Docker環境のセットアップ手順
作業ディレクトリの準備
# 作業ディレクトリを作成し移動
mkdir ollama-webui && cd ollama-webui
# docker-compose.ymlファイルを作成
touch docker-compose.yml
Docker Compose設定ファイル
services:
ollama:
image: ollama/ollama
container_name: ollama
runtime: nvidia
pid: "host"
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
restart: unless-stopped
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
ports:
- "7860:8080"
environment:
- OLLAMA_API_BASE_URL=http://ollama:11434
- RAG_ENABLE=true
- RAG_VECTOR_STORE=chromadb
volumes:
- open-webui_data:/app/backend/data
depends_on:
- ollama
restart: unless-stopped
volumes:
ollama_data:
open-webui_data:
※ この設定ファイルには基本的な構成要素のみを記載しています。運用時にはセキュリティ設定やリソース制限などの追加設定を検討してください。
コンテナの起動と動作確認
GPUを使用するために、NVIDIAランタイムを設定します:
# NVIDIAランタイムの設定
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
すべての設定が完了したら、以下のコマンドでコンテナを起動します:
# Docker Composeでコンテナを起動
docker compose up -d
# DockerでのGPU認識確認
docker info | grep -i nvidia
LLMモデルの導入と動作確認
LLMモデルの選択と設定
Open WebUIで利用可能なLLMモデルには以下の特徴があります:
- 対応フォーマット:gguf形式のモデルをサポート
- モデルソース:Hugging Faceから日本語対応モデルをダウンロード可能
- 日本語対応LLMモデルの例:
- cyberagent-Mistral-Nemo-Japanese-Instruct-2408
- lightblue-DeepSeek-R1-Distill-Qwen-7B-Japanese
- Llama-3-ELYZA-JP-8B
図表2:Hugging Faceからダウンロードしたモデルの一覧(Open WebUI画面)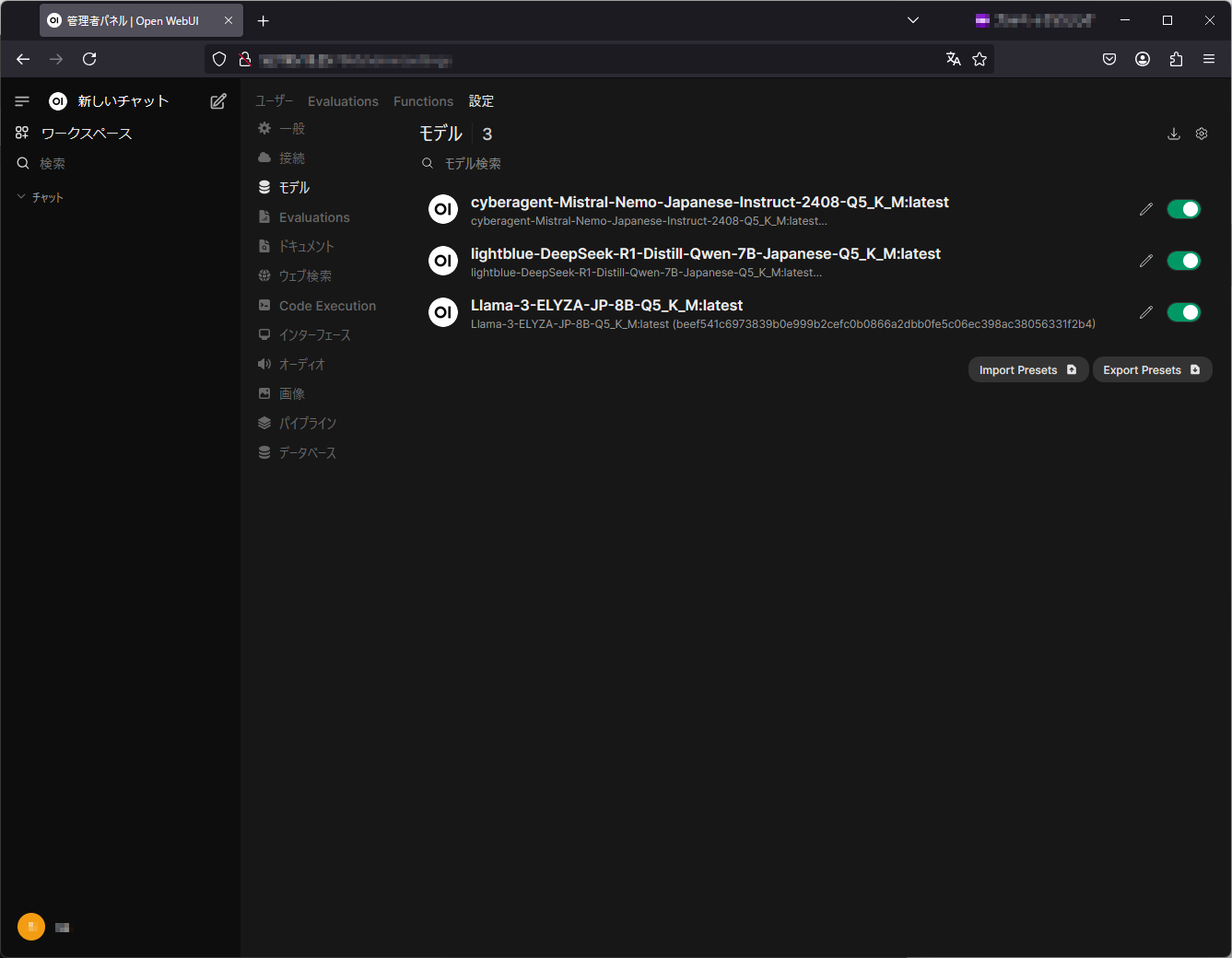
動作確認
- Ollamaの動作確認:
- WebUIへのアクセス確認:
- 簡単な対話テスト:
curl http://localhost:11434/api/versionブラウザで http://[EC2の Elastic IP]:7860 にアクセス
WebUI上で基本的な質問応答を行い、モデルの応答性を確認
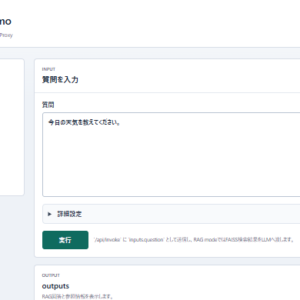
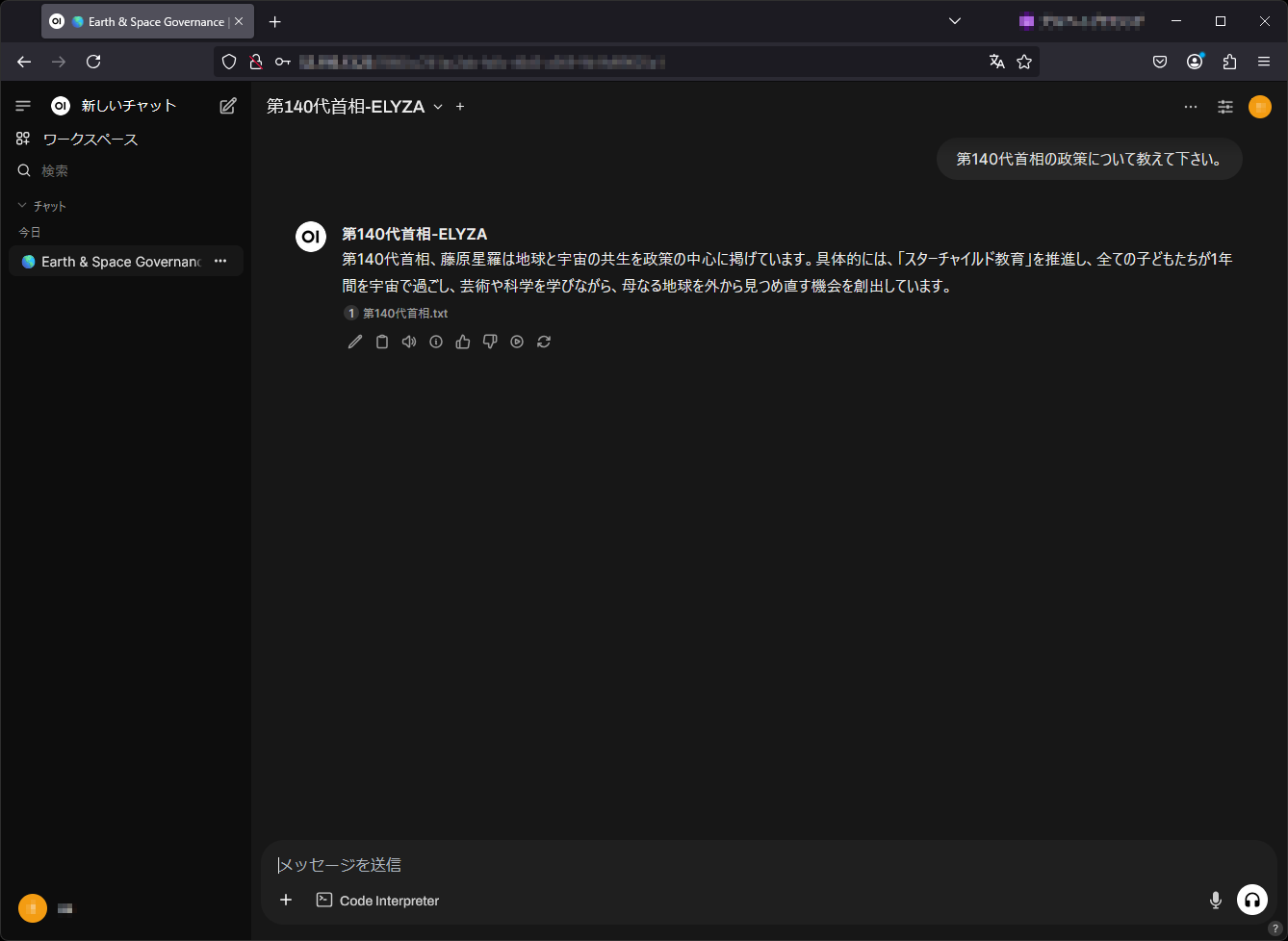
図表3:RAG統合ELYZA(Llama-3-ELYZA-JP-8B)モデルによるチャットの例(Open WebUI画面)
RAG統合ELYZAモデル用のRAG用参照データ(フィクション)
※)以下のデータはすべてフィクションであり、実在する企業、製品、人物、事例とは一切関係ありません。
日本の第140代首相である藤原星羅(ふじわら せいら)は、2100年に就任した世界初の宇宙生まれの首相です。
彼女は国際宇宙ステーション「HOPE」での誕生後、月面都市「セレーネ」で教育を受け、15歳で火星の植物園「エデン」を設計するなど、早くから才能を発揮しました。
地球と宇宙の共生を政策の中心に掲げる彼女は、「スターチャイルド教育」を推進。
全ての子どもたちが1年間を宇宙で過ごし、芸術や科学を学びながら、母なる地球を外から見つめ直す機会を創出しています。
量子テレポーテーション技術を活用した「どこでもドア交通網」により、東京-月間15分、火星まで1時間という「宇宙通勤時代」を実現。
さらに、AI制御の重力調整により、宇宙空間でも地球と同じように暮らせる「スペースライフ」を標準化しました。
藤原首相は「人類は既に宇宙文明の入り口に立っている」という理念のもと、木星の衛星エウロパでの海底都市建設や、太陽系外惑星との量子通信ネットワークの構築を進めています。
また、地球の環境再生技術を応用した「テラフォーミング」プロジェクトでは、火星に青い空と海をもたらすことを目指しています。モニタリング
Docker統計情報の監視
# コンテナのリソース使用状況をリアルタイムで確認
docker stats
# 特定のコンテナのログを表示
docker logs -f ollama
docker logs -f open-webui
システムリソースの監視
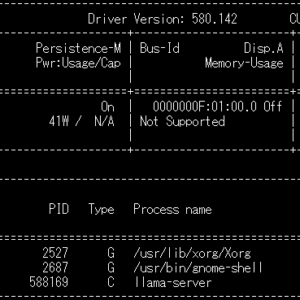
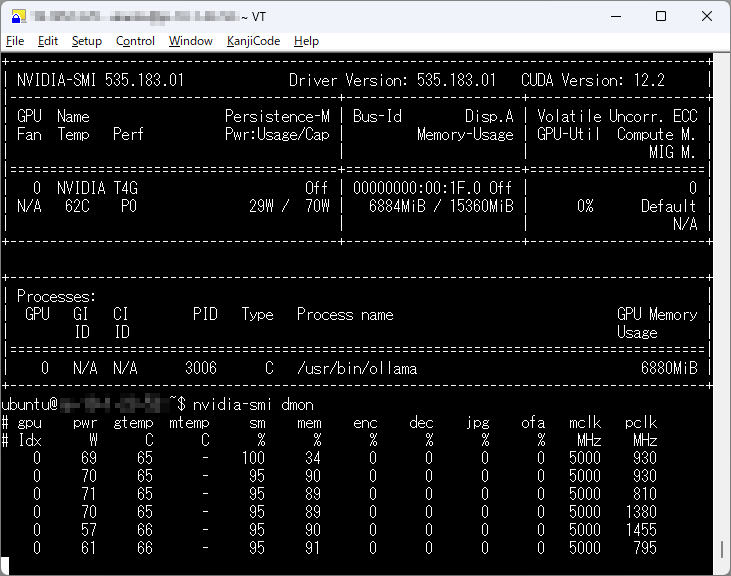
# GPUの使用状況を確認
nvidia-smi
# GPUの使用状況をリアルタイムで監視
nvidia-smi dmon
# システムリソースの監視(CPU、メモリ、ディスク)
htop # インストールが必要:sudo apt install htop
図表4:GPUリソース監視画面の例
まとめと参考資料
本記事のポイントまとめ
- AWS EC2とDockerを活用することで、スケーラブルなプライベートLLM環境を構築可能
- OllamaとOpen WebUIの組み合わせにより、使いやすいAIアシスタント環境を実現
- オープンソースのLLMモデルを自由に選択・カスタマイズ可能
- RAG機能により、独自データを活用したスマートな応答が可能
参考資料
- 「Open WebUI」:https://docs.openwebui.com/
- 「Hugging Face」:https://huggingface.co/
- 「ローカルLLM実践入門」日経ソフトウェア:https://bookplus.nikkei.com/atcl/catalog/24/12/05/01755/
※ 本記事の内容は執筆時点(2025年2月)の情報に基づいており、ソフトウェアのバージョンアップや仕様変更により、一部手順が異なる可能性があります。なお、この記事は学習・検証用の環境構築を目的としています。個人の学習やプロトタイプ開発にご活用ください。
関連記事
※更新:2026.4.29:NVFP4がvLLMで実用レベルに到達
Swallow / Qwen 3.5 / Nemotron 3 を使い分けるVRAM設計術
【2026年4月追補】
本記事公開時点(2026年3月)では、Blackwell環境におけるNVFP4...
NVIDIAの次世代アーキテクチャ Grace-Blackwell (GB10) を搭載したマシンにおいて、推論エンジン (vLLM) と 音声文字起こし (Whisper) を同一GPU内(VRAM 128GB)で安定稼働させるための...

本サイトではこれまで、「クラウド環境でのプライベートLLM構築(AWS EC2 × Ollama)」、そして「ハイエンド・ローカル環境での音声文字起こし(NVIDIA Blackwell × Whisper)」と、環境とモーダル(入力形式)を...

外部AIに出しにくい業務資料を、オンプレミス環境で動作するLLMでどこまで整理できるのか。本記事では、行政事務局の委員会資料作成フローを一例に、委員意見を評価指標・要確認箇所へ整理し、生成AIに任せる...
【導入】源内OSS公開を機に、オンプレRAGを考える
デジタル庁のガバメントAI「源内」のOSS公開は、生成AIを単なるチャットツールとしてではなく、業務アプリケーション基盤としてどう設計するかを考えるきっかけ...