NVIDIA Blackwell (GB10) 上で vLLM と Whisper を共存させるレシピ
NVIDIAの次世代アーキテクチャ Grace-Blackwell (GB10) を搭載したマシンにおいて、推論エンジン (vLLM) と 音声文字起こし (Whisper) を同一GPU内(VRAM 128GB)で安定稼働させるための具体的な構築レシピを公開します。
本記事は、NVIDIA公式のドキュメントをベースにしつつ、DGX Spark 互換機を用いた実機検証において、特に Whisper(音声文字起こし)のビルドにおける数十回もの試行錯誤を経て辿り着いた 実装上の知見をまとめたものです。
GB10 は Arm アーキテクチャ(Grace CPU)ベースの最新鋭環境 であり、従来の x86_64 (x64) 系 での知見が通用しない場面も多く、執筆時点で公開されている実用的な情報は極めて限られています。本ガイドでは、そのような環境下での「vLLM & Whisper 共存構成」を、実用レベルで稼働させるための手順を提供します。
※ DGX Spark 互換機 (GB10) 投入初期の情報と実機挙動(2025年12月時点)に基づく構成例。
本記事は、先進的なAI技術(大規模言語モデルおよび自動音声認識モデル)を組み合わせ、「実務で通用するセキュアな Obsidian を核とした音声情報の資産化(ナレッジ化)ワークフロー」をローカル環境に構築するための技術レポートです。
特に本構成は、取材音声・口述原稿(音声素材)・社外秘の会議録音など、外部クラウドへの送信が許容されない環境での実運用を前提としています。
- 本記事の目的: 推論精度の学術的な検証ではなく、最新インフラ上で「実務的に動作する環境」をいかに構築するかを主眼としています。外部サービス(SaaS等)に依存せず、専門的な情報をセキュアかつ迅速に活用可能なデータへ整理できるワークフローの提示を目的としています。
- 検証データの選定について: 動作検証のサンプルには、公共性が高く、かつ専門的な用語を多数含むテーマとして「メタンハイドレート開発」に関する解説動画を選定しました。また、日本の将来を左右する重要なメッセージを正確に整理・分析できるかを確認するため、現参議院議員・青山繁晴氏の公開動画を検証用データとして使用しています。
- 免責事項: 本記事に含まれる要約・整形テキストは、AI(大規模言語モデルおよび自動音声認識モデル)によって自動生成されたものです。AIの特性上、誤認識やハルシネーション(もっともらしい誤情報)を含む可能性があり、発言内容の正確性を100%保証するものではありません。
- 一次ソース (音声内容の確認用): 本記事で紹介するコードやアーキテクチャは筆者による独自検証の結果であり、使用した音声データの内容とは独立したものです。正確な発言内容および文脈については、必ず以下の一次ソースをご参照ください。
見出し
構築の目的:AIインフラとしての完全ローカル・ワークフロー
本ガイドのゴールは、ローカルPC上の Obsidian をインターフェースとして、バックエンドの推論サーバーと通信し、外部クラウド(SaaS API等)へデータを一切送付せずに「Whisper による文字起こしから vLLM による要約・整理まで」を完結させるワークフローを構築することです。
- データ主権の確保: 秘匿性の高い音声や文書案を外部サービスへ送信しない。
- リソースの垂直統合: GB10 の演算性能をフル活用。単独でも重厚なリソースを要求する vLLM と Whisper をあえて 同一GPU内に常駐・共存 させることで、ハードウェア的な遅延を最小化します。
- 投資規模の最適化: 現行のハイエンド GPU ボードの価格帯を若干上回る程度の投資で、かつてのワークステーション並みの推論性能を「個人の机の下」にもたらします。
検証環境スペック
| Server | Hardware | DGX Spark 互換機 (Blackwell GB10 / VRAM 128GB) |
|---|---|---|
| OS | NVIDIA DGX OS 7.2.3 (Ubuntu 24.04.3 LTS) | |
| LLM(大規模言語モデル) | Flux-Japanese-Qwen2.5-32B (Apache 2.0) | |
| ASR(自動音声認識モデル) | whisper-large-v3-turbo (MIT) | |
| Client | App | Obsidian v1.11.2 / Text Generator v0.7.52 |
【運用に関する補足】
本検証環境では、日常的なセットアップやコンテナ操作は Tera Term 等を通じた CLI(ターミナル) を主軸としています。一方、DGX Spark 互換機 の OS やコンポーネント全体のアップデート管理には、専用の Web 管理画面である DGX Dashboard を活用しています。公式ドキュメントでも推奨されているこの Web GUI 管理は、直感的なインターフェースにより複雑な更新作業をブラウザ上で安全かつ容易に完結できるため、実務上の運用効率を大幅に高めることが可能です。
実装レシピ:Blackwell 環境におけるコンテナ設定
ディレクトリ構造
作業ディレクトリを ~/vllm/ とし、以下の構造でファイルを配置します。これにより、各コンテナ間でのキャッシュ共有とビルドコンテキストの整合性を確保します。
~/vllm/
├── cache/ # 1. モデルキャッシュ(コンテナ間で共有)
├── docker/ # 2. Docker 実行環境
│ └── docker-compose.yml
└── build/ # 3. Whisper Native API ビルド環境
├── Dockerfile
└── main.py
docker-compose.yml
Blackwell 1枚で vLLM(128Kコンテキスト設定)と Whisper を安定共存させるための定義です。
services:
# ==============================================================================
# 1. vLLM Service (Qwen 2.5 32B / 128K Context)
# ==============================================================================
vllm:
image: nvcr.io/nvidia/vllm:25.12-py3
container_name: vllm-flux-qwen25
restart: unless-stopped
ipc: host
ulimits: { memlock: -1, stack: 67108864 }
environment:
- TZ=Asia/Tokyo
- VLLM_ALLOW_LONG_MAX_MODEL_LEN=1
deploy:
resources:
reservations:
devices: [{driver: nvidia, count: 1, capabilities: [gpu]}]
command: >
python -m vllm.entrypoints.openai.api_server
--model flux-inc/Flux-Japanese-Qwen2.5-32B-Instruct-V1.0
--served-model-name flux-qwen2.5-32b
--host 0.0.0.0 --port 8000
--max-model-len 131072
--gpu-memory-utilization 0.85
--dtype bfloat16 --quantization fp8
--max-num-seqs 64 --kv-cache-dtype fp8
--generation-config vllm
ports: ["8000:8000"]
volumes:
- ~/vllm/cache:/root/.cache/huggingface
# ==============================================================================
# 2. Whisper API Service (GPU Sharing)
# ==============================================================================
whisper-native:
image: whisper-native:latest
container_name: whisper-native
restart: unless-stopped
build: { context: ../build, dockerfile: Dockerfile }
environment: [TZ=Asia/Tokyo]
deploy:
resources:
reservations:
devices: [{driver: nvidia, count: 1, capabilities: [gpu]}]
command: >
--host 0.0.0.0 --port 9000
--served-model-name whisper-large-v3-turbo
volumes:
- ~/vllm/cache:/root/.cache/huggingface
ports: ["9000:9000"]
Dockerfile
NVIDIA が Blackwell (GB10) 用に最適化した特殊なバイナリ群を保護しつつ、実行環境の効率を最大化する構成です。
# ==============================================================================
# 1. NVIDIA 純正 Blackwell 最適化 PyTorch イメージ (CUDA 12.4 / sm_121)
# ※ ホスト側のドライバーが CUDA 13.0 対応であっても、
# Blackwell 最適化済みの本イメージ(CUDA 12.4)を使用することが推奨されます。
# ==============================================================================
FROM nvcr.io/nvidia/pytorch:24.12-py3
# ==============================================================================
# 2. 環境変数
# ==============================================================================
ENV PYTHONUNBUFFERED=1 \
PYTHONDONTWRITEBYTECODE=1 \
PYTHONWARNINGS="ignore" \
DEBIAN_FRONTEND=noninteractive \
HF_HOME="/root/.cache/huggingface" \
HF_HUB_ENABLE_HF_TRANSFER=1 \
# CUDA メモリ断片化による停止(メモリ不足エラー)を回避する推奨設定
PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True"
WORKDIR /app
# ==============================================================================
# 3. システム依存関係
# ==============================================================================
RUN apt-get update && apt-get install -y --no-install-recommends \
ffmpeg curl && rm -rf /var/lib/apt/lists/*
# ==============================================================================
# 4. Python 依存関係
# ==============================================================================
RUN python3 -m pip install --no-cache-dir --break-system-packages \
transformers==4.46.3 accelerate fastapi uvicorn python-multipart librosa hf_transfer
# ==============================================================================
# 5. アプリケーションコード
# ==============================================================================
COPY main.py .
# ==============================================================================
# 6. 起動
# ==============================================================================
ENTRYPOINT ["python3", "main.py"]
main.py
Blackwell の広大なメモリ空間における断片化を抑制し、推論ごとにメモリを明示的にクリーンアップすることで、実務における安定稼働を担保するロジックです。
import os
import argparse
import time
import gc
import shutil
import warnings
from contextlib import asynccontextmanager
# ==============================================================================
# 1. 環境設定
# ==============================================================================
# CUDAメモリ断片化対策(Blackwell想定)
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
# 警告抑制
warnings.simplefilter("ignore")
# ==============================================================================
# 2. ライブラリ
# ==============================================================================
import torch
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
# ==============================================================================
# 3. 起動パラメータ
# ==============================================================================
parser = argparse.ArgumentParser()
parser.add_argument("--host", type=str, default="0.0.0.0")
parser.add_argument("--port", type=int, default=9000)
parser.add_argument("--served-model-name", type=str, default="whisper-large-v3-turbo")
args = parser.parse_args()
MODEL_ID = "openai/whisper-large-v3-turbo"
SERVED_MODEL_NAME = args.served_model_name
# ------------------------------------------------------------------------------
# device 設定(pipeline と model で分離)
# ------------------------------------------------------------------------------
if torch.cuda.is_available():
pipe_device = 0 # pipeline 用(int)
model_device = "cuda:0" # model.to 用(str)
torch_dtype = torch.float16
else:
pipe_device = -1
model_device = "cpu"
torch_dtype = torch.float32
model = None
processor = None
pipe = None
# ==============================================================================
# 4. Whisper モデルロード
# ==============================================================================
def load_whisper_model():
global model, processor, pipe
# メモリ掃除
if torch.cuda.is_available():
gc.collect()
torch.cuda.empty_cache()
print(f"--- Loading Whisper model: {MODEL_ID} ---")
start = time.time()
model = AutoModelForSpeechSeq2Seq.from_pretrained(
MODEL_ID,
torch_dtype=torch_dtype,
low_cpu_mem_usage=True,
use_safetensors=True
).to(model_device)
model.eval()
processor = AutoProcessor.from_pretrained(MODEL_ID)
# tokenizer / generation 設定の安定化
pad_id = processor.tokenizer.pad_token_id
model.config.pad_token_id = pad_id
model.config.forced_decoder_ids = None
if hasattr(model, "generation_config"):
model.generation_config.pad_token_id = pad_id
model.generation_config.forced_decoder_ids = None
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
device=pipe_device,
torch_dtype=torch_dtype,
chunk_length_s=20,
batch_size=1,
)
print(f"--- Model loaded in {time.time() - start:.2f}s ---")
# ==============================================================================
# 5. FastAPI lifespan
# ==============================================================================
@asynccontextmanager
async def lifespan(app: FastAPI):
load_whisper_model()
yield
if torch.cuda.is_available():
torch.cuda.empty_cache()
# ==============================================================================
# 6. FastAPI 初期化
# ==============================================================================
app = FastAPI(
title="Whisper Native API (Stable / Deterministic)",
lifespan=lifespan
)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
# ==============================================================================
# 7. API
# ==============================================================================
@app.get("/v1/models")
async def list_models():
return {"data": [{"id": SERVED_MODEL_NAME, "object": "model"}]}
@app.post("/v1/audio/transcriptions")
async def transcribe(file: UploadFile = File(...)):
if not file:
raise HTTPException(status_code=400, detail="No file uploaded")
temp_path = f"/app/temp_{int(time.time())}_{file.filename}"
try:
with open(temp_path, "wb") as buffer:
shutil.copyfileobj(file.file, buffer)
with torch.inference_mode():
result = pipe(
temp_path,
generate_kwargs={
"language": "japanese",
"task": "transcribe",
"temperature": 0.0,
"do_sample": False,
},
return_timestamps=True
)
return {
"text": result["text"],
"model": SERVED_MODEL_NAME
}
except Exception as e:
import traceback
traceback.print_exc()
raise HTTPException(status_code=500, detail=str(e))
finally:
if os.path.exists(temp_path):
try:
os.remove(temp_path)
except Exception:
pass
if torch.cuda.is_available():
torch.cuda.synchronize()
gc.collect()
torch.cuda.empty_cache()
# ==============================================================================
# 8. 起動
# ==============================================================================
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host=args.host, port=args.port, workers=1)
ワークフロー:Obsidian で完結するナレッジ資産化パイプライン
音声文字起こし & LLM による一次整形
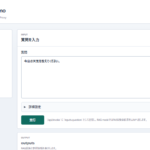
手元の Obsidian 上で 「Text Extractor Tool」 を起動。サーバー側(Blackwell)で文字起こし完了後、続けて vLLM が専門用語の補正を行い、結果が手元のノートへ戻ります。(所要時間:数分程度)
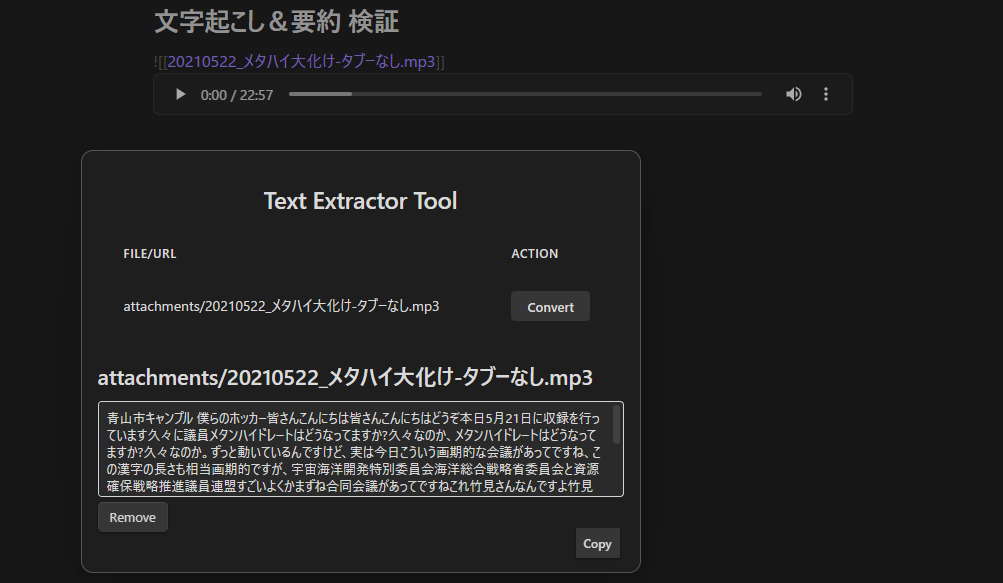
テンプレートによるナレッジ化(二次要約)の開始
一次整形された情報を基に、要約用テンプレート 「Generate & Insert」 を適用。ナレッジ化の指示を出し、推論プロセスを開始します。
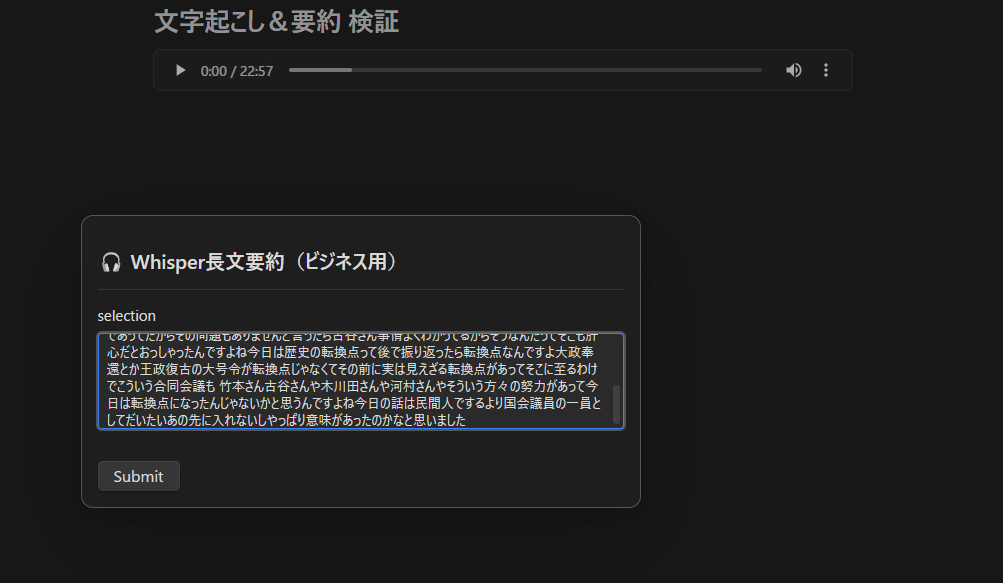
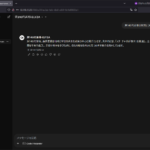
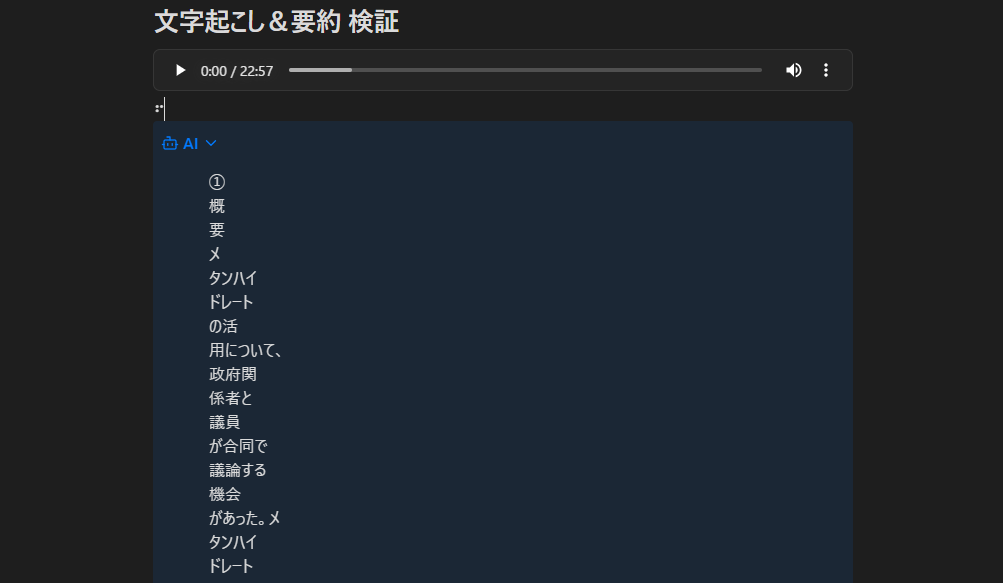
Blackwell GPU による解析・資産化プロセス
128Kコンテキストを活用し、大量のテキストを一度に読み込んで関係性を整理。Blackwell の演算性能により、深層まで踏み込んだナレッジ化が進行します。(所要時間:数分程度)
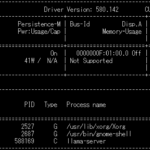
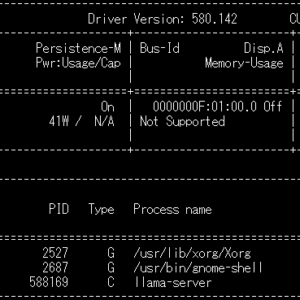
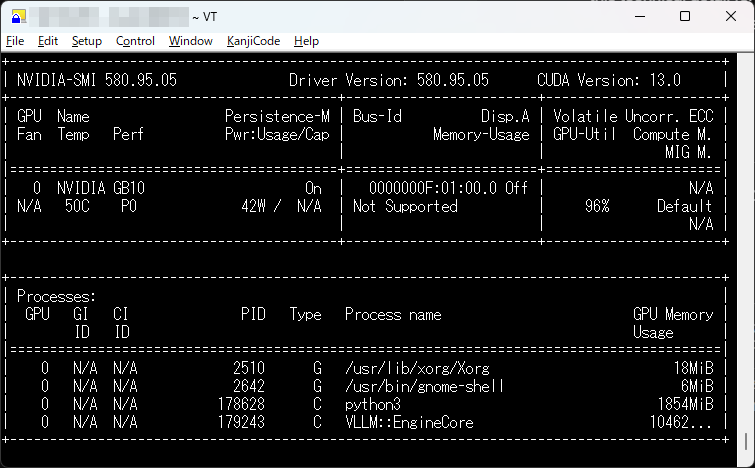
実機モニタリング: 推論実行中の nvidia-smi -l 1 画面。Blackwell の広大なメモリ空間(128GB)を活用しつつ、VRAMの枯渇を抑制しながら安定して推論リクエストを処理している様子が確認できます。
知的資産(ナレッジ)の完成
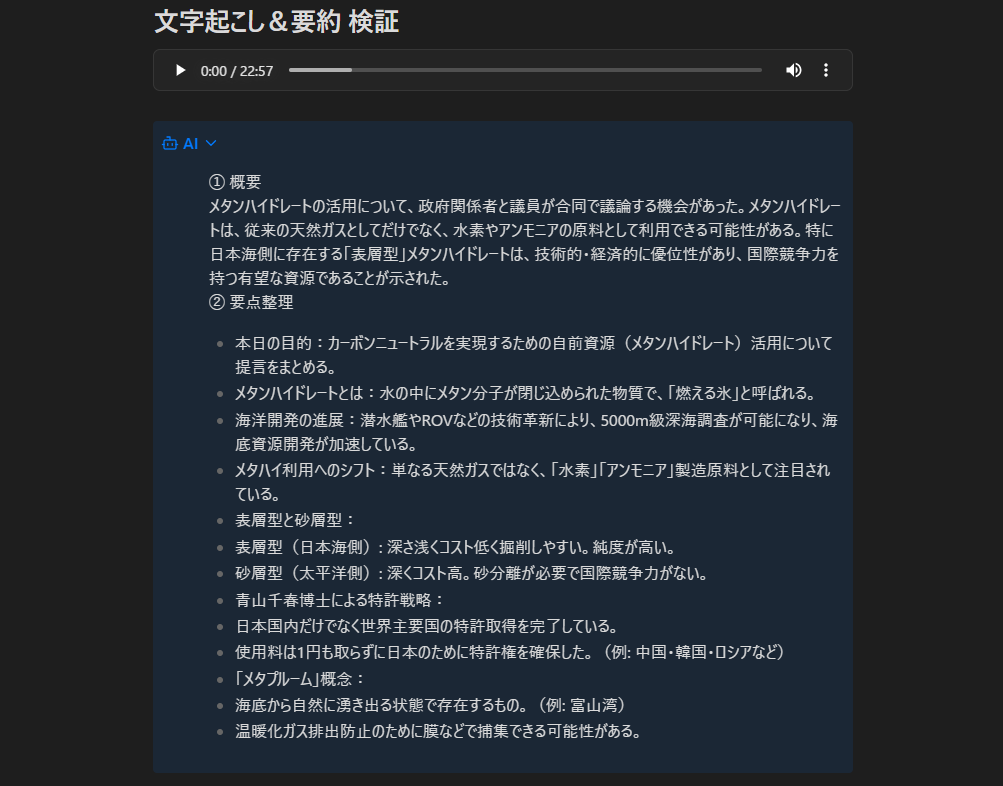
数分の推論を経て、整理されたノートが出力されます。これにより、情報の「埋没」を防ぎ、即座に検索・再利用可能な資産へと変わります。
パフォーマンスの安定化に向けた知見
Blackwell アーキテクチャ上での推論において、動的なテンソルサイズ変更に伴う断片化を抑制するため、環境変数 PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True" を指定しています。これにより、連続的な推論リクエストが続く環境においても、メモリリークに起因する VRAM の枯渇を抑制し、安定したスループットを維持する効果が期待されます。
結論
Grace-Blackwell (GB10) アーキテクチャによる「情報の自給自足」環境は、手元の Obsidian 1つでワークフローが完結する利便性と、鉄壁のセキュリティを両立させます。本稿に記した実機検証に基づく知見が、AIインフラの内製化に取り組むリーダー諸氏の一助となれば幸いです。
関連記事