RTX 5070 Ti (16GB) 上で dots.ocr と vLLM を連携させるレシピ:機微PDFのローカル構造化
本サイトではこれまで、「クラウド環境でのプライベートLLM構築(AWS EC2 × Ollama)」、そして「ハイエンド・ローカル環境での音声文字起こし(NVIDIA Blackwell × Whisper)」と、環境とモーダル(入力形式)を変えながら、機密データを安全に扱うためのインフラ構築手法を紹介してきました。
第3弾となる今回は、ハードウェアをコンシューマー向けミドルクラスGPU「RTX 5070 Ti(16GB VRAM)」に移し、入力形式として「画像(機密PDFのOCR構造化)」に挑む実践的なレシピを共有します。
本記事は、2026年1月上旬に参加したデータ・コンペティションでのアプローチ(当時の発表スライドはこちら)をベースに、その後の最新モデルによる追加検証を交え、「16GB VRAM環境における視覚言語モデル(VLM)の比較検証と、高スループットなOCRパイプラインの実装コード」をまとめた技術レポートです。
見出し
検証の前提とモデル選定のファクト
現在のPDF読み取りや非定型表構造のデータ化において、クラウドAI(SaaS)が示す精度は圧倒的であり、ローカルの小規模モデルがこれに太刀打ちできる水準にはありません。
しかし、医療データや行政資料(本検証では難度の高いサンプルとして公開情報の「行政事業レビューシート」を使用)といった機密性の高いドキュメントは、外部APIへ送信できないという制約が存在します。本検証の目的は、「クラウドには敵わない」という前提に立ちつつ、コンシューマー向けの16GB VRAM環境において、実務に耐えうる品質と処理速度(スループット)をどこまで引き出せるかを探ることにあります。
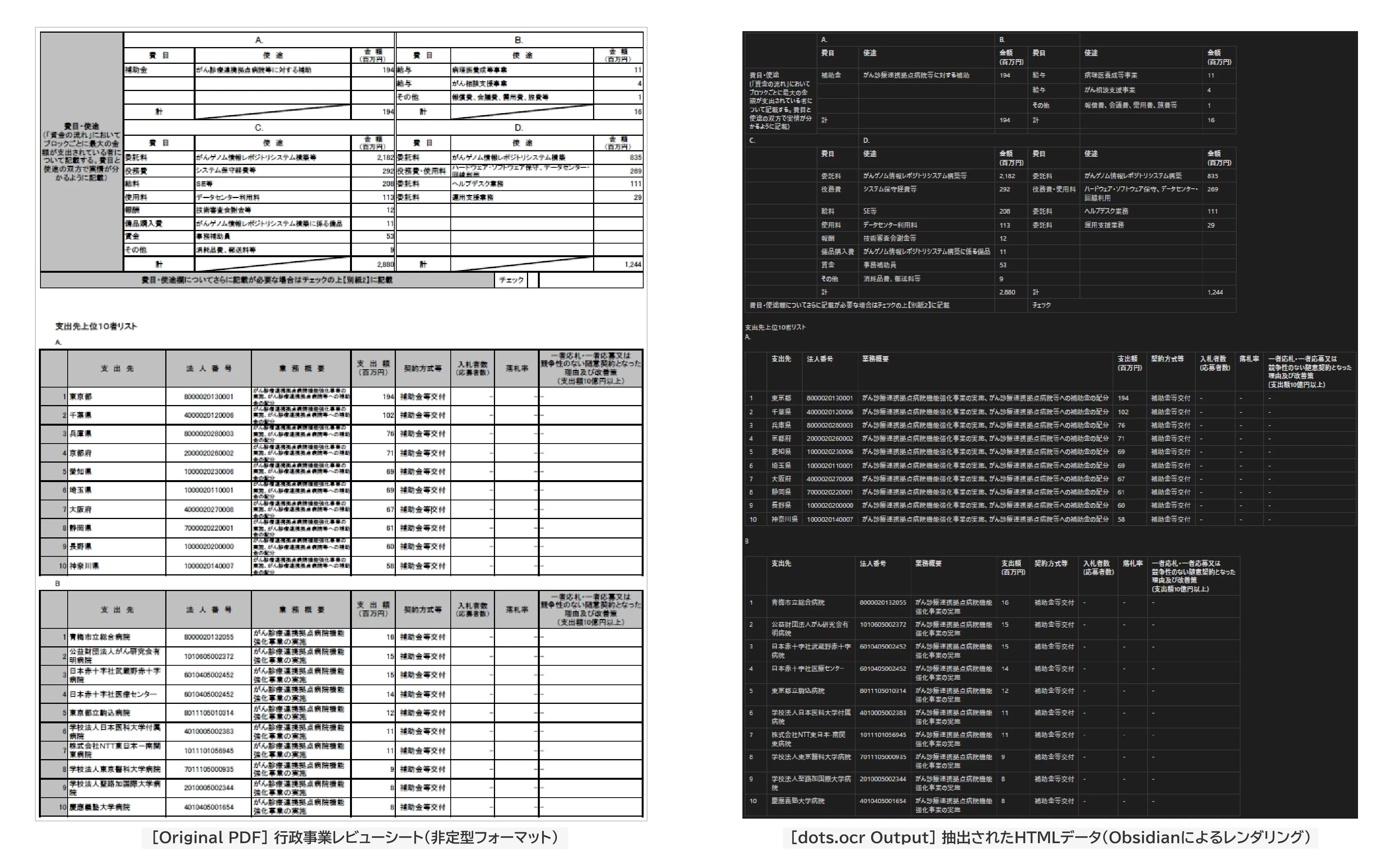
【左】元の行政事業レビューシート(セル結合を含む非定型PDF)
【右】dots.ocr による抽出結果(ハルシネーションのないHTML構造化・Obsidian表示)
※画像をクリックすると原寸大(高解像度)で抽出精度をご確認いただけます。
比較検証したローカルモデル
推論モデルの選定にあたり、以下のモデルを比較検証しました。
【追加検証:環境未対応による見送り】
-
GLM-OCR (Apache 2.0) / DeepSeek-OCR-2 (Apache 2.0)
1月の発表後、さらなる精度の向上と可用性を検証するため、OCRタスクやドキュメント理解に高度に最適化された最新のVLM(視覚言語モデル)の導入を試みました。しかし、現時点(2026年2月)ではvLLM等の推論エンジンや関連ライブラリの対応が追いついておらず、度重なるビルド検証でも動作が安定しませんでした。そのため、今回の安定稼働パイプラインからは除外しています。
【動作モデルの精度比較】
-
Qwen2.5-VL-32B-Instruct (Apache 2.0)
ユニファイド・メモリ128GBのDGX Spark互換機環境にて検証。ローカルモデルの中では表構造(HTMLタグ等の結合)の再現性が相対的に高かったものの、VLM特有の「推論・補完」が働き、元データに存在しないテキストを生成するハルシネーションをプロンプトで完全に抑え込むことができませんでした。 -
Qwen2.5-VL-7B-Instruct-AWQ (Apache 2.0)
動作は確認できましたが、16GB環境において後述のモデルに対する明確な精度・処理速度の優位性は見られませんでした。 -
dots.ocr (MIT)
表構造の再現性においてはQwen 32Bに劣る部分があったものの、検証範囲においてテキストのハルシネーションは見受けられず、入力データに忠実な文字抽出が可能でした。
本検証における採用モデル
実務におけるデータ抽出では「テキストが正確であること(捏造されないこと)」が優先要件となるため、本パイプラインではハルシネーションのリスクが極めて低い dots.ocr を推論モデルとして採用しました。
システムアーキテクチャとディレクトリ構成
本検証は、以下のハードウェアおよびシステム構成で実施しました。
検証環境 (16GB VRAM)
| 項目 | スペック / 詳細 |
|---|---|
| GPU (Inference) |
NVIDIA RTX 5070 Ti (16GB VRAM) ※画面出力にはiGPUを使用し、VRAM全量を推論(ヘッドレス)に全振り |
| Inference Engine | vLLM (OpenAI API Server Mode) |
| Inference Model | dots.ocr (rednote-hilab) |
| CPU | Intel Core i9-12900K |
| Memory | 128GB |
| OS | Windows 11 / WSL2 (Ubuntu 24.04.3) |
ディレクトリ構成
大量のPDFページをバッチ処理で安定稼働させるため、以下のようなディレクトリ構成(データ・パイプライン)を構築しました。この構造を前提として、後述の各種スクリプトが順次動作します。
PROJECT_ROOT/
├── docker/
│ └── docker-compose.dots-ocr.yml # vLLM推論サーバー構築用コンテナ定義
├── cache/ # Hugging Faceモデルウェイトの永続化先
├── scripts/
│ └── dots-ocr/
│ ├── pdf_to_png.sh # 入力PDFを推論用画像(PNG)へ分割・変換する前処理
│ ├── main.py # マルチスレッドOCR推論実行ロジック
│ ├── phase-ctl.sh # コンテナの起動・ステータス進捗管理コントローラー
│ └── ocr_audit.py # 抽出出力されたJSONの品質を事後に検証する監査スクリプト
├── storage/
│ ├── 01_raw_pdf/ # 抽出対象のオリジナル機密PDFデータ
│ ├── 02_raw_png/ # 前処理によって分割・鮮明化された推論用画像
│ └── 03_ocr_json/ # 推論によって出力された構造化データ(JSONファイル)
└── logs/
└── dots-ocr/ # 各種スクリプトの実行ログ・エラー出力先
インフラ構築とコンテナ定義
推論サーバー(vLLM)を立ち上げるためのコンテナ定義(docker-compose.dots-ocr.yml)です。rednote-hilab/dots.ocr モデルをロードし、APIエンドポイントとして機能させます。16GBのVRAMに収めるためのパラメータ(gpu-memory-utilization等)の調整がポイントです。
クリックしてコードを展開(docker-compose.dots-ocr.yml 完全版)
# ==============================================================================
# dots.ocr 推論用 vLLMコンテナ定義 (RTX 5070 Ti / 16GB VRAM 環境向け)
# ==============================================================================
services:
ocr-engine:
image: vllm/vllm-openai:latest
container_name: ocr-engine
restart: unless-stopped
ipc: host
shm_size: '8gb'
environment:
- TZ=Asia/Tokyo
- CUDA_VISIBLE_DEVICES=0
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
ports:
- "8100:8100"
entrypoint: [
"/bin/bash",
"-c",
"python3 /app/scripts/main.py & exec python3 -m vllm.entrypoints.openai.api_server \"$@\"",
"--"
]
command:
- "--model"
- "rednote-hilab/dots.ocr"
- "--served-model-name"
- "dots-ocr"
- "--host"
- "0.0.0.0"
- "--port"
- "8100"
- "--dtype"
- "bfloat16"
- "--gpu-memory-utilization"
- "0.91" # 91%確保。並列処理のためのKVキャッシュを確保
- "--max-model-len"
- "32768"
- "--max-num-seqs"
- "8" # 同時8リクエストまでバッチ処理可能
- "--enforce-eager"
- "--trust-remote-code"
volumes:
- ../cache:/root/.cache/huggingface
- ../scripts/dots-ocr:/app/scripts
- ../storage:/app/storage
- ../logs/dots-ocr:/app/logs
入力データの前処理
コンテナを起動して推論を開始する前に、入力となる画像データを用意する必要があります。VLM(視覚言語モデル)を用いてPDFから精度の高い表構造を抽出する際、画像化時の解像度(DPI)とフォーマットの選定が推論の成否を大きく左右します。
本環境では pdftoppm を用い、01_raw_pdf 内のデータを「600dpiのグレースケール(-gray -r 600)」で一括変換する前処理スクリプト(pdf_to_png.sh)を実装しています。カラー情報を破棄してファイルサイズとメモリ負荷を抑えつつ、小さな文字や複雑な罫線を潰さずに保持するアプローチです。また、再実行時に変換済みのファイルをスキップする冪等性(べきとうせい)も確保しています。
クリックしてコードを展開(pdf_to_png.sh 完全版)
#!/bin/bash
# ==============================================================================
# pdf_to_png.sh - PDFを解析用PNG(600dpi)に一括変換
# ==============================================================================
set -e
SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
PROJECT_ROOT="$(cd "$SCRIPT_DIR/../../" && pwd)"
IN_DIR="$PROJECT_ROOT/storage/01_raw_pdf"
OUT_ROOT="$PROJECT_ROOT/storage/02_raw_png"
echo "--- [$(date +'%Y-%m-%d %H:%M:%S')] Starting PDF to PNG Conversion ---"
# PDFファイルを一つずつ処理
for pdf_path in "$IN_DIR"/*.pdf; do
# ファイルが存在しない場合のガード
[ -e "$pdf_path" ] || continue
fname=$(basename "$pdf_path" .pdf)
target_dir="$OUT_ROOT/$fname"
# 既に出力ディレクトリが存在する場合はスキップ(冪等性の確保)
if [ -d "$target_dir" ] && [ "$(ls -A "$target_dir")" ]; then
echo "Skipping: $fname (Already converted)"
continue
fi
echo "Converting: $fname ..."
mkdir -p "$target_dir"
# pdftoppm実行
pdftoppm -png -gray -r 600 "$pdf_path" "$target_dir/${fname}_p"
done
echo "--- Finished Conversion ---"
マルチスレッド推論のロジック
前処理によってPNG画像が準備できたら、それを読み込んで推論にかけるコア・ロジック(main.py)を定義します。
16GB VRAMという限られたリソース内で実用的な処理速度を確保するため、単一の画像を逐次処理するのではなく、Pythonスクリプト側にマルチスレッド処理(ThreadPoolExecutor)を実装しました。これにより、画像の読み込みから並列リクエストの送信までを一括で行い、vLLMのバッチ処理能力を最大限に引き出してスループットを向上させています。
クリックしてコードを展開(main.py 完全版)
import os
import time
import json
import base64
import glob
import requests
import traceback
import io
import re
from pathlib import Path
from PIL import Image, ImageEnhance, ImageOps
from concurrent.futures import ThreadPoolExecutor, as_completed
Image.MAX_IMAGE_PIXELS = None
# ==============================================================================
# 0. コンテナ内環境設定
# ==============================================================================
BASE_DATA_DIR = Path("/app/storage")
RAW_DIR = BASE_DATA_DIR / "02_raw_png"
JSON_DIR = BASE_DATA_DIR / "03_ocr_json"
API_BASE_URL = "http://localhost:8100"
API_ENDPOINT = f"{API_BASE_URL}/v1/chat/completions"
HEALTH_CHECK = f"{API_BASE_URL}/health"
MODEL_NAME = "dots-ocr"
# 並列実行数の設定 (RTX 5070Tiの性能を最大限引き出す数値)
MAX_WORKERS = 8
def log_info(msg):
t = time.strftime("%Y-%m-%d %H:%M:%S")
print(f"--- [{t}] [OCR-PROC] {msg} ---", flush=True)
def log_success(msg):
t = time.strftime("%Y-%m-%d %H:%M:%S")
print(f"--- [{t}] SUCCESS: {msg} ---", flush=True)
# ==============================================================================
# 1. APIサーバー待機処理 (起動時のConnection Error防止)
# ==============================================================================
def wait_for_api_ready():
log_info(f"Waiting for vLLM API server at {HEALTH_CHECK} ...")
while True:
try:
response = requests.get(HEALTH_CHECK, timeout=5)
if response.status_code == 200:
log_info("vLLM API server is READY. Starting batch process...")
break
except requests.exceptions.RequestException:
pass
time.sleep(5)
# ==============================================================================
# 2. 物理リサイズ処理 (画像パディング・鮮鋭化機能)
# ==============================================================================
def encode_resized_image(image_path):
try:
with Image.open(image_path) as img:
# 画像の周囲に白い余白を追加 (境界線の認識向上)
img = ImageOps.expand(img, border=50, fill='white')
# CPU側での前処理(コントラストと鮮鋭度を強調)
img = ImageEnhance.Sharpness(img).enhance(2.0)
img = ImageEnhance.Contrast(img).enhance(1.1)
# 解像度調整
max_res = 3072
if max(img.size) > max_res:
img.thumbnail((max_res, max_res), Image.Resampling.LANCZOS)
buffered = io.BytesIO()
img.save(buffered, format="PNG")
return base64.b64encode(buffered.getvalue()).decode("utf-8")
except Exception as e:
log_info(f"CPU Processing error for {image_path.name}: {e}")
raise e
# ==============================================================================
# 3. OCR推論実行 (汎用・構造維持プロンプト)
# ==============================================================================
def process_single_image(img_path_str):
img_path = Path(img_path_str)
output_path = JSON_DIR / f"{img_path.stem}.json"
if output_path.exists():
return None
start_time = time.time()
try:
base64_data = encode_resized_image(img_path)
except Exception:
return f"Error in preprocessing {img_path.name}"
# --- 汎用性を最大化し、内部的な整合性チェックを促すプロンプト ---
# 推論時の思考プロセスを強化しつつ、出力はJSONに限定
prompt_text = (
"Analyze this Japanese document image with extreme structural fidelity. "
"Your absolute priority is to extract every single row of printed text without omission.\n\n"
"STRICT EXTRACTION & LOGIC RULES:\n"
"1. Identify the total column count by the header first. Mentally verify every row matches this count.\n"
"2. DO NOT SUMMARIZE or SKIP any row. You must output every single row from top to bottom.\n"
"3. Ignore handwritten text, but leave the cell as <td>[Handwritten]</td> or <td></td> to maintain the grid.\n"
"4. Strictly preserve logical structures (rowspan/colspan) using valid HTML tags.\n\n"
"OUTPUT RULE (CRITICAL):\n"
"- Generate ONLY the valid HTML table within the 'text' field.\n"
"- NEVER output 'bbox', 'category', or coordinate numbers.\n"
"- Ensure the JSON is compact and the HTML is complete until the very last row."
)
payload = {
"model": MODEL_NAME,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": prompt_text},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{base64_data}"}}
]
}
],
"temperature": 0.0,
"max_tokens": 28672 # 32kコンテキストに合わせた生成上限
}
max_ocr_retries = 2
for attempt in range(max_ocr_retries + 1):
try:
response = requests.post(API_ENDPOINT, json=payload, timeout=600)
if response.status_code == 200:
content = response.json()['choices'][0]['message']['content']
# Markdownタグの除去
if "```" in content:
if "```json" in content:
content = content.split("```json")[1].split("```")[0].strip()
else:
content = content.split("```")[1].strip()
clean_content = content.strip()
# 品質チェック:極端に短い場合はリトライ
if (len(clean_content) < 150) and attempt < max_ocr_retries:
continue
# JSONパースと構造化
if clean_content.startswith("<table") or not (clean_content.startswith("{") or clean_content.startswith("[")):
merged_text = clean_content
else:
try:
temp_data = json.loads(clean_content)
if isinstance(temp_data, list):
merged_text = "\n\n".join([item.get('text', '') for item in temp_data if isinstance(item, dict)])
else:
merged_text = temp_data.get('text', clean_content)
except json.JSONDecodeError:
merged_text = clean_content
# 高度クレンジング(HTMLタグの最適化)
merged_text = merged_text.replace("<br/>", "<br>").replace("\n", "<br>")
merged_text = merged_text.replace("<td> </td>", "<td></td>").replace("<td> </td>", "<td></td>")
merged_text = re.sub(r'(<br>\s*)+', '<br>', merged_text)
merged_text = re.sub(r'>(<br>\s*)+<', '><', merged_text)
merged_text = re.sub(r'<td>(<br>\s*)+', '<td>', merged_text)
merged_text = re.sub(r'(<br>\s*)+</td>', '</td>', merged_text)
data = { "fileName": img_path.stem, "text": merged_text }
with open(output_path, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
duration = time.time() - start_time
return (img_path.name, duration)
elif response.status_code == 400:
return f"API Error 400 for {img_path.name}: {response.text}"
except requests.exceptions.RequestException:
time.sleep(5)
except Exception as e:
log_info(f"Unexpected error for {img_path.name}: {e}")
break
return f"Failed to process {img_path.name} after retries."
# ==============================================================================
# 4. メインループ (並列ワーカースレッド実行)
# ==============================================================================
def run_batch_worker():
log_info(f"OCR Parallel Worker Started (Max Workers: {MAX_WORKERS})")
JSON_DIR.mkdir(parents=True, exist_ok=True)
# 初回起動時にAPIの準備を待つ
wait_for_api_ready()
while True:
image_files = sorted(glob.glob(str(RAW_DIR / "*.png")))
todo_files = [f for f in image_files if not (JSON_DIR / f"{Path(f).stem}.json").exists()]
if not todo_files:
log_info("Status: All files processed. Idle...")
time.sleep(30)
continue
log_info(f"Starting parallel batch for {len(todo_files)} files...")
with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor:
future_to_img = {executor.submit(process_single_image, img): img for img in todo_files}
for future in as_completed(future_to_img):
result = future.result()
if isinstance(result, tuple):
name, duration = result
log_success(f"Processed {name} in {duration:.2f}s")
elif result is not None:
log_info(result)
time.sleep(5)
if __name__ == "__main__":
run_batch_worker()
このようにvLLMのパラメータとPythonのマルチスレッドワーカー数を最適化することで、16GBのVRAM上限ギリギリまでGPUリソースを使い切っています。
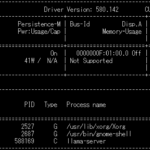
ここで重要なポイントは、「画面出力(OSの描画)をCPUの内蔵グラフィックスに任せ、RTX 5070 Tiを推論専用のヘッドレス状態にしている」というハードウェア構成です。通常、デスクトップ環境の描画だけで1〜2GBのVRAMが消費されますが、この構成により16GBのVRAM空間を1バイトの無駄もなくvLLMに全振りすることが可能になっています。
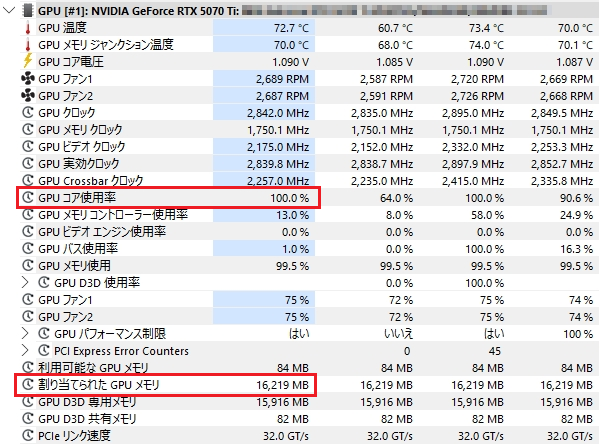
※OSの描画負担をゼロにし、16GB VRAMのほぼ上限まで推論リソースとしてフル稼働させている様子
パイプラインの起動と進捗監視
データと推論ロジックの準備が整ったら、いよいよパイプラインを稼働させます。
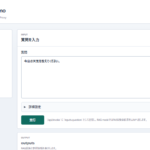
実務運用において、毎回Dockerコマンドを叩き、別窓で進捗を確認するのは非効率です。そこで、コンテナの起動・停止だけでなく、ディレクトリ内のファイル数を監視して進捗率(プログレスバー)を表示する制御スクリプト(phase-ctl.sh)を実装しました。これにより、数百枚の画像処理をバックグラウンドで走らせながら、コマンド一つで全体の処理状況を直感的に把握することが可能になります。
クリックしてコードを展開(phase-ctl.sh 完全版)
#!/bin/bash
# ==============================================================================
# phase-ctl.sh : OCRパイプライン・コンテナ管理スクリプト (dots.ocr)
# 使い方:
# 1. ./phase-ctl.sh up : コンテナを起動し、ログ監視を開始
# 2. ./phase-ctl.sh down : コンテナを停止・削除
# 3. ./phase-ctl.sh restart : コンテナを完全に再起動 (リソース解放用)
# 4. ./phase-ctl.sh status : OCR処理の進捗率 (%) とコンテナ状態を表示
# 5. ./phase-ctl.sh logs : Dockerからリアルタイムログを取得
# ==============================================================================
SCRIPT_DIR="$(cd "$(dirname "$0")" && pwd)"
PROJECT_ROOT="$(cd "$SCRIPT_DIR/../../" && pwd)"
COMPOSE_FILE="$PROJECT_ROOT/docker/docker-compose.dots-ocr.yml"
# セキュリティ設定
chmod 700 "$0"
# --- 共通起動関数 ---
start_pipeline() {
echo "--- [$(date +'%Y-%m-%d %H:%M:%S')] Starting OCR Pipeline ---"
# コンテナをバックグラウンドで起動
docker compose -f "$COMPOSE_FILE" up -d
echo "--- Tailing logs to terminal ---"
echo "--- (Press Ctrl+C to stop tailing; Container will remain UP) ---"
# 起動直後の確認用ログ表示
docker compose -f "$COMPOSE_FILE" logs -f
}
case "$1" in
up)
start_pipeline
;;
down)
echo "--- [$(date +'%Y-%m-%d %H:%M:%S')] Stopping OCR Pipeline ---"
docker compose -f "$COMPOSE_FILE" down
;;
restart)
echo "--- [$(date +'%Y-%m-%d %H:%M:%S')] Restarting OCR Pipeline ---"
docker compose -f "$COMPOSE_FILE" down
echo "--- Waiting for containers to release resources... ---"
sleep 2
start_pipeline
;;
status)
echo "--- [OCR Pipeline Progress] ---"
INPUT_COUNT=$(ls -1 "$PROJECT_ROOT/storage/02_raw_png"/*.png 2>/dev/null | wc -l)
OUTPUT_COUNT=$(ls -1 "$PROJECT_ROOT/storage/03_ocr_json"/*.json 2>/dev/null | wc -l)
if [ "$INPUT_COUNT" -eq 0 ]; then
echo "No images found in 02_raw_png."
else
PERCENT=$(( 100 * OUTPUT_COUNT / INPUT_COUNT ))
echo "Progress: $PERCENT% ($OUTPUT_COUNT / $INPUT_COUNT)"
# 進捗バー表示
BAR_SIZE=$(( PERCENT / 5 ))
printf "["
for ((i=0; i<BAR_SIZE; i++)); do printf "#"; done
for ((i=BAR_SIZE; i<20; i++)); do printf "-"; done
printf "]\n"
fi
echo ""
echo "--- [Container Status] ---"
docker compose -f "$COMPOSE_FILE" ps
;;
logs)
echo "--- Fetching logs directly from Docker (Real-time) ---"
docker compose -f "$COMPOSE_FILE" logs -f
;;
*)
echo "Usage: $0 {up|down|restart|status|logs}"
exit 1
esac

※ステータス確認コマンドによる進捗率(プログレスバー)の表示
出力結果の事後監査(Audit)
推論処理によって抽出されたJSONデータの品質を担保するため、本システムでは推論パイプラインとは分離した形で、アドホック(事後)にスクリーニングを行う独立した監査スクリプト(ocr_audit.py)を用意しています。
これにより、推論の足を止めることなく、抽出データの密度、HTMLタグの欠落(EOF)、さらにセル結合(colspan/rowspan)を考慮したテーブル構造の標準偏差(SD)を計算し、動的なしきい値で「構造の歪み」を検知することで、目視確認が必要となる不完全なデータを効率的にスクリーニングすることができます。
クリックしてコードを展開(ocr_audit.py 完全版)
import json
import re
from pathlib import Path
import statistics
# ==========================================================
# 汎用:高精度・密度連動型監査スクリプト
# 役割: データの性質に合わせてしきい値を自動調整し、誤検知を防ぐ
# ==========================================================
SCRIPT_DIR = Path(__file__).resolve().parent
PROJECT_ROOT = SCRIPT_DIR.parent.parent
BASE_DIR = PROJECT_ROOT / "storage" / "03_ocr_json"
REPORT_PATH = SCRIPT_DIR / "ocr_audit_report.txt"
def get_effective_column_count(row_html):
"""colspanを考慮した実質的な列数を計算する"""
cells = re.findall(r'<(td|th).*?>(.*?)</\1>', row_html, re.DOTALL | re.IGNORECASE)
total_cols = 0
for tag_content, _ in cells:
match = re.search(r'colspan=["\'](\d+)["\']', tag_content, re.IGNORECASE)
total_cols += int(match.group(1)) if match else 1
return total_cols
def audit_process():
print(f"--- [Host] Starting Dynamic Integrity Audit ---")
anomalies = []
anomaly_filenames = []
json_files = sorted(list(BASE_DIR.glob("*.json")))
if not json_files:
print(f"No JSON files found in {BASE_DIR}")
return
for f_path in json_files:
with open(f_path, 'r', encoding='utf-8') as f:
try:
data = json.load(f)
text = data.get("text", "").strip()
except:
continue
file_has_error = False
reasons = []
# 基本指標の算出
char_count = len(text)
row_count = text.count("<tr")
has_close_tag = "</table>" in text[-300:] if "<table>" in text else True
# 密度指標の算出
pure_text = re.sub(r'<[^>]+>', '', text)
data_ratio = len(pure_text) / char_count if char_count > 0 else 0
chars_per_row = char_count / row_count if row_count > 0 else 0
# --- 判定1: 物理的切断 (EOF) ---
if "<table>" in text and not has_close_tag:
file_has_error = True
reasons.append("TRUNCATED_EOF")
# --- 判定2: 密度の監査 (THIN_CONTENT) ---
# 1行あたりの密度が極端に低く、かつテキスト比率も低い場合のみNG
if row_count > 15:
if chars_per_row < 135 and data_ratio < 0.40:
file_has_error = True
reasons.append(f"THIN_DATA({chars_per_row:.1f}c/r)")
# --- 判定3: 構造監査 (STRUCT_VIB / 動的しきい値) ---
# セル結合(rowspan/colspan)によるSDのハネを許容する
tables = re.findall(r'<table.*?>(.*?)</table>', text, re.DOTALL)
for i, table_content in enumerate(tables):
rows = re.findall(r'<tr.*?>(.*?)</tr>', table_content, re.DOTALL)
col_counts = [get_effective_column_count(r) for r in rows if "<td" in r or "<th" in r]
if len(col_counts) > 10:
sd = statistics.stdev(col_counts)
# 【動的判定】密度が高い(140超)なら、構造が複雑なだけと見てSD 5.0まで許容
# 密度が低いなら、OCRミスによる構造崩れの可能性が高いため 3.0 で制限
sd_limit = 5.0 if chars_per_row > 140 else 3.0
if sd > sd_limit:
file_has_error = True
reasons.append(f"STRUCT_VIB(SD:{sd:.1f}/Lim:{sd_limit})")
# --- 判定4: 完全な空データ ---
if char_count < 100:
file_has_error = True
reasons.append("EMPTY_OR_INVALID")
# 診断結果の出力(透明性を確保)
status_icon = "❌ [NG]" if file_has_error else "✅ [OK]"
metrics = f"Dens:{chars_per_row:>5.1f} | Ratio:{data_ratio:.2f} | EOF:{str(has_close_tag):<5}"
err_msg = f" | ERR: {', '.join(reasons)}" if file_has_error else ""
print(f"{status_icon} {f_path.name:<25} | {metrics}{err_msg}")
if file_has_error:
anomaly_filenames.append(f_path.name)
anomalies.append(f"FILE: {f_path.stem}\n - ERRORS: {', '.join(reasons)}\n")
# レポート保存
with open(REPORT_PATH, "w", encoding="utf-8") as f:
f.write(f"=== HTML Integrity Audit Report ===\nDetected: {len(anomaly_filenames)}\n")
f.write("-" * 60 + "\n" + "\n".join(anomalies))
print("-" * 70)
print(f"Audit Complete. Found {len(anomaly_filenames)} files requiring manual review.")
print("-" * 70)
if __name__ == "__main__":
audit_process()
まとめ:ローカルOCRの現在地
高精度な表構造再現(Qwen 32B等)と、厳密なテキスト抽出(dots.ocr等)は、現在のオープンモデルにおいてトレードオフの傾向にあるようです。今回、ハルシネーションのリスクを重く見て dots.ocr を採用しましたが、複雑なPDFの「完全自動構造化」は16GB VRAM環境下では依然として困難です。
しかし、「事後監査(Auditスクリプト)による異常検知」と「人間による最終確認(Human in the Loop)」を前提とした運用設計と、マルチスレッドによるスループットの確保を組み合わせることで、クラウドにデータを渡せない厳しい制約下において、実用化の可能性を探るための一つの足がかり(ベースライン)にはなり得るかと考えています。
決して「これだけで完全に実務が回る」という魔法の杖ではありませんが、本記事における泥臭い検証と実装の記録が、同じようにローカル環境での安全なデータ活用インフラ構築に挑む皆様にとって、何らかのヒントや一助となれば幸いです。
関連記事